 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain No Evil: Selective Masking for Task-guided Pre-training
Paper and Code
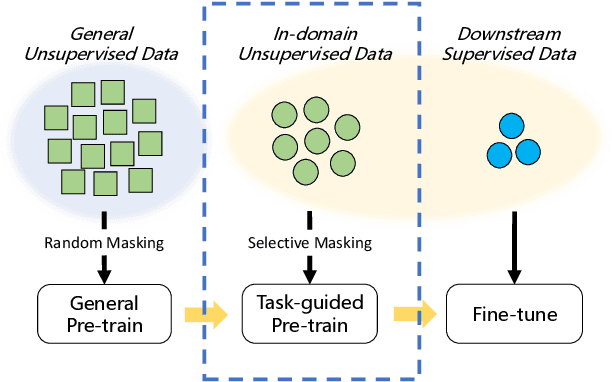
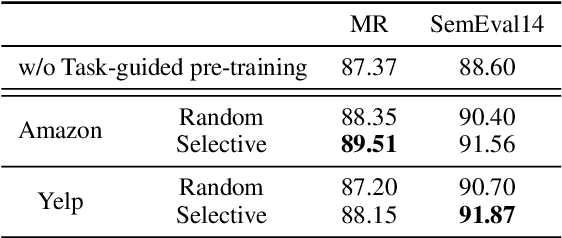
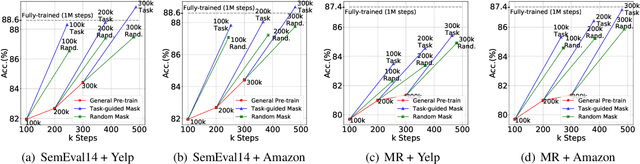

Recently, pre-trained language models mostly follow the pre-training-then-fine-tuning paradigm and have achieved great performances on various downstream tasks. However, due to the aimlessness of pre-training and the small in-domain supervised data scale of fine-tuning, the two-stage models typically cannot capture the domain-specific and task-specific language patterns well. In this paper, we propose a selective masking task-guided pre-training method and add it between the general pre-training and fine-tuning. In this stage, we train the masked language modeling task on in-domain unsupervised data, which enables our model to effectively learn the domain-specific language patterns. To efficiently learn the task-specific language patterns, we adopt a selective masking strategy instead of the conventional random masking, which means we only mask the tokens that are important to the downstream task. Specifically, we define the importance of tokens as their impacts on the final classification results and use a neural model to learn the implicit selecting rules. Experimental results on two sentiment analysis tasks show that our method can achieve comparable or even better performance with less than 50\% overall computation cost, which indicates our method is both effective and efficient. The source code will be released in the future.