 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Adaptive Contextual Bandits for Resource Constraint based Recommendation
Paper and Code
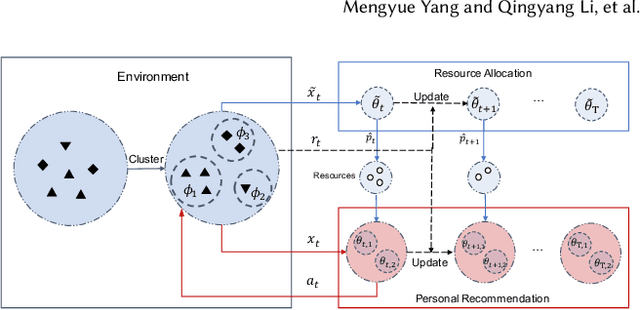
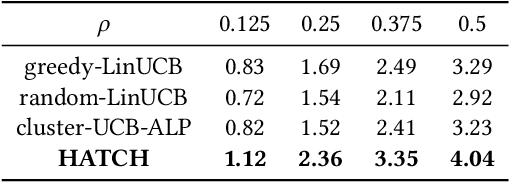
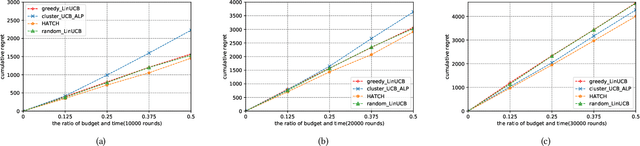

Contextual multi-armed bandit (MAB) achieves cutting-edge performance on a variety of problems. When it comes to real-world scenarios such as recommendation system and online advertising, however, it is essential to consider the resource consumption of exploration. In practice, there is typically non-zero cost associated with executing a recommendation (arm) in the environment, and hence, the policy should be learned with a fixed exploration cost constraint. It is challenging to learn a global optimal policy directly, since it is a NP-hard problem and significantly complicates the exploration and exploitation trade-off of bandit algorithms. Existing approaches focus on solving the problems by adopting the greedy policy which estimates the expected rewards and costs and uses a greedy selection based on each arm's expected reward/cost ratio using historical observation until the exploration resource is exhausted. However, existing methods are hard to extend to infinite time horizon, since the learning process will be terminated when there is no more resource. In this paper, we propose a hierarchical adaptive contextual bandit method (HATCH) to conduct the policy learning of contextual bandits with a budget constraint. HATCH adopts an adaptive method to allocate the exploration resource based on the remaining resource/time and the estimation of reward distribution among different user contexts. In addition, we utilize full of contextual feature information to find the best personalized recommendation. Finally, in order to prove the theoretical guarantee, we present a regret bound analysis and prove that HATCH achieves a regret bound as low as $O(\sqrt{T})$. The experimental results demonstrate the effectiveness and efficiency of the proposed method on both synthetic data sets and the real-world applications.