 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanNuke Dataset Extension, Insights and Baselines
Paper and Code
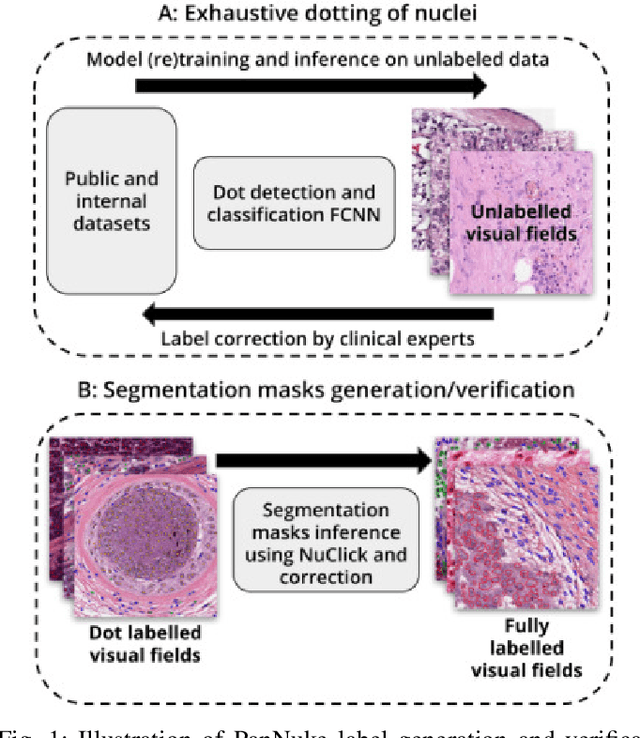
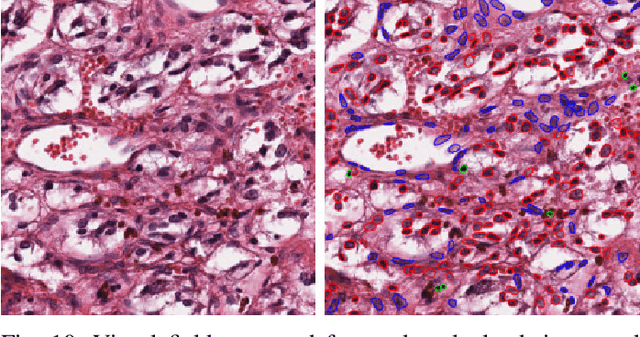
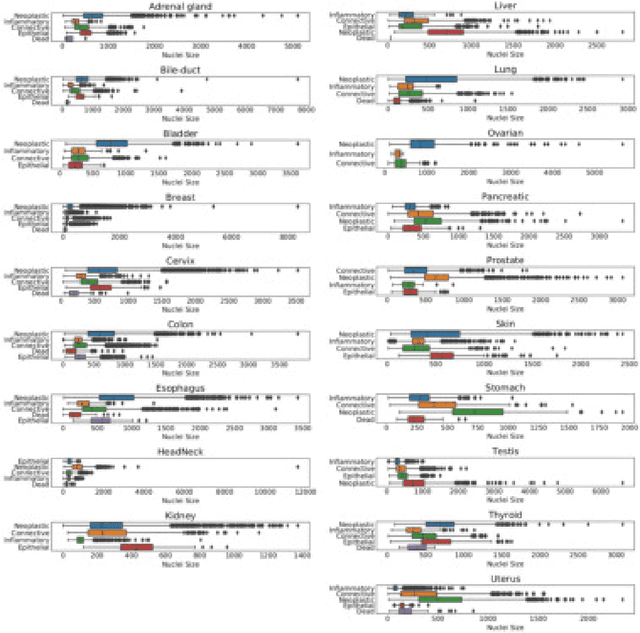
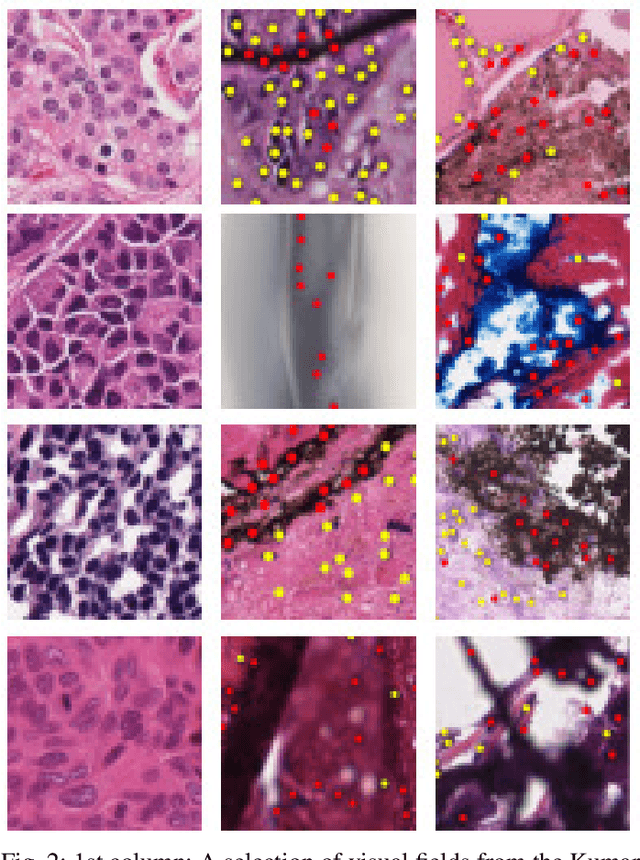
The emerging area of computational pathology (CPath) is ripe ground for the application of deep learning (DL) methods to healthcare due to the sheer volume of raw pixel data in whole-slide images (WSIs) of cancerous tissue slides. However, it is imperative for the DL algorithms relying on nuclei-level details to be able to cope with data from `the clinical wild', which tends to be quite challenging. We study, and extend recently released PanNuke dataset consisting of ~200,000 nuclei categorized into 5 clinically important classes for the challenging tasks of segmenting and classifying nuclei in WSIs. Previous pan-cancer datasets consisted of only up to 9 different tissues and up to 21,000 unlabeled nuclei and just over 24,000 labeled nuclei with segmentation masks. PanNuke consists of 19 different tissue types that have been semi-automatically annotated and quality controlled by clinical pathologists, leading to a dataset with statistics similar to the clinical wild and with minimal selection bias. We study the performance of segmentation and classification models when applied to the proposed dataset and demonstrate the application of models trained on PanNuke to whole-slide images. We provide comprehensive statistics about the dataset and outline recommendations and research directions to address the limitations of existing DL tools when applied to real-world CPath applications.