 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mean-field Analysis of Deep ResNet and Beyond: Towards Provable Optimization Via Overparameterization From Depth
Paper and Code
Mar 11, 2020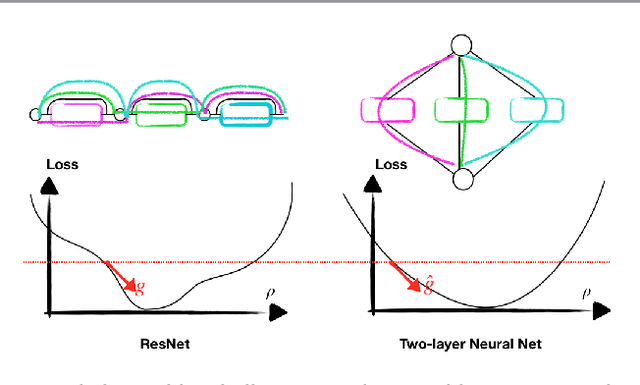
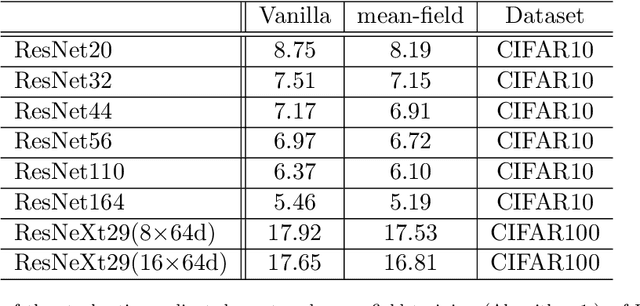
Training deep neural networks with stochastic gradient descent (SGD) can often achieve zero training loss on real-world tasks although the optimization landscape is known to be highly non-convex. To understand the success of SGD for training deep neural networks, this work presents a mean-field analysis of deep residual networks, based on a line of works that interpret the continuum limit of the deep residual network as an ordinary differential equation when the network capacity tends to infinity. Specifically, we propose a new continuum limit of deep residual networks, which enjoys a good landscape in the sense that every local minimizer is global. This characterization enables us to derive the first global convergence result for multilayer neural networks in the mean-field regime. Furthermore, without assuming the convexity of the loss landscape, our proof relies on a zero-loss assumption at the global minimizer that can be achieved when the model shares a universal approximation property. Key to our result is the observation that a deep residual network resembles a shallow network ensemble, i.e. a two-layer network. We bound the difference between the shallow network and our ResNet model via the adjoint sensitivity method, which enables us to apply existing mean-field analyses of two-layer networks to deep networks. Furthermore, we propose several novel training schemes based on the new continuous model, including one training procedure that switches the order of the residual blocks and results in strong empirical performance on the benchmark datasets.