 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClean-Label Backdoor Attacks on Video Recognition Models
Paper and Code


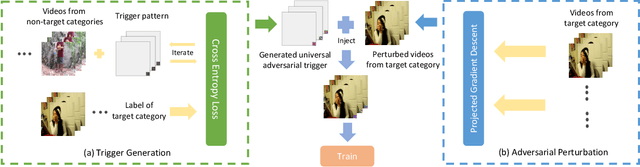

Deep neural networks (DNNs) are vulnerable to backdoor attacks which can hide backdoor triggers in DNNs by poisoning training data. A backdoored model behaves normally on clean test images, yet consistently predicts a particular target class for any test examples that contain the trigger pattern. As such, backdoor attacks are hard to detect, and have raised severe security concerns in real-world applications. Thus far, backdoor research has mostly been conducted in the image domain with image classification models. In this paper, we show that existing image backdoor attacks are far less effective on videos, and outline 4 strict conditions where existing attacks are likely to fail: 1) scenarios with more input dimensions (eg. videos), 2) scenarios with high resolution, 3) scenarios with a large number of classes and few examples per class (a "sparse dataset"), and 4) attacks with access to correct labels (eg. clean-label attacks). We propose the use of a universal adversarial trigger as the backdoor trigger to attack video recognition models, a situation where backdoor attacks are likely to be challenged by the above 4 strict conditions. We show on benchmark video datasets that our proposed backdoor attack can manipulate state-of-the-art video models with high success rates by poisoning only a small proportion of training data (without changing the labels). We also show that our proposed backdoor attack is resistant to state-of-the-art backdoor defense/detection methods, and can even be applied to improve image backdoor attacks. Our proposed video backdoor attack not only serves as a strong baseline for improving the robustness of video models, but also provides a new perspective for more understanding more powerful backdoor attacks.