 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Semantic Video Segmentation with Per-frame Inference
Paper and Code
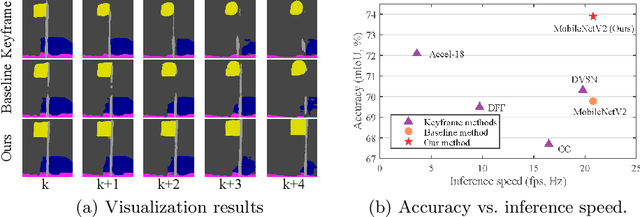
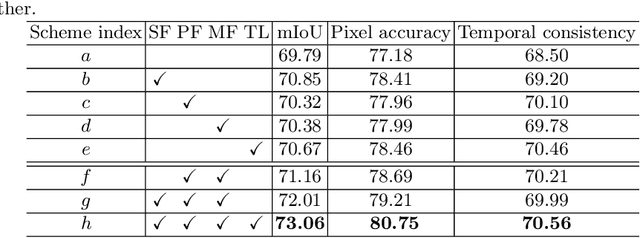
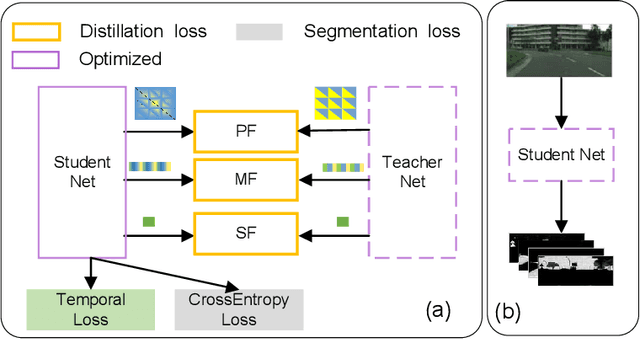
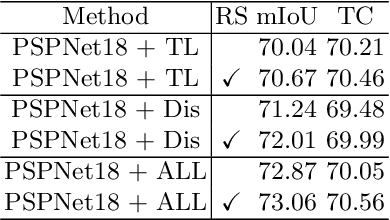
In semantic segmentation, most existing real-time deep models trained with each frame independently may produce inconsistent results for a video sequence. Advanced methods take into considerations the correlations in the video sequence, e.g., by propagating the results to the neighboring frames using optical flow, or extracting the frame representations with other frames, which may lead to inaccurate results or unbalanced latency. In this work, we process efficient semantic video segmentation in a per-frame fashion during the inference process. Different from previous per-frame models, we explicitly consider the temporal consistency among frames as extra constraints during the training process and embed the temporal consistency into the segmentation network. Therefore, in the inference process, we can process each frame independently with no latency, and improve the temporal consistency with no extra computational cost and post-processing. We employ compact models for real-time execution. To narrow the performance gap between compact models and large models, new knowledge distillation methods are designed. Our results outperform previous keyframe based methods with a better trade-off between the accuracy and the inference speed on popular benchmarks, including the Cityscapes and Camvid. The temporal consistency is also improved compared with corresponding baselines which are trained with each frame independently. Code is available at: https://tinyurl.com/segment-video