 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Gate: A Simple and Effective Gating Mechanism for Recurrent Units
Paper and Code
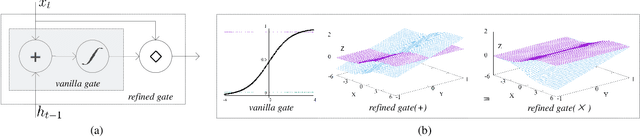
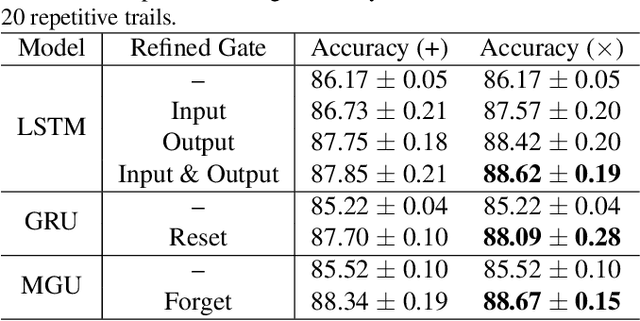
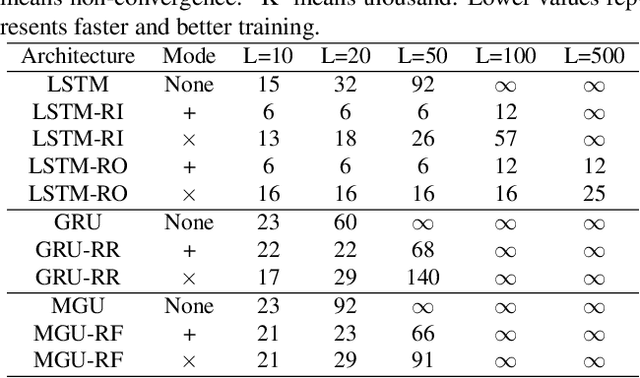
Recurrent neural network (RNN) has been widely studied in sequence learning tasks, while the mainstream models (e.g., LSTM and GRU) rely on the gating mechanism (in control of how information flows between hidden states). However, the vanilla gates in RNN (e.g. the input gate in LSTM) suffer from the problem of gate undertraining mainly due to the saturating activation functions, which may result in failures of learning gating roles and thus the weak performance. In this paper, we propose a new gating mechanism within general gated recurrent neural networks to handle this issue. Specifically, the proposed gates directly short connect the extracted input features to the outputs of vanilla gates, denoted as refined gates. The refining mechanism allows enhancing gradient back-propagation as well as extending the gating activation scope, which, although simple, can guide RNN to reach possibly deeper minima. We verify the proposed gating mechanism on three popular types of gated RNNs including LSTM, GRU and MGU. Extensive experiments on 3 synthetic tasks, 3 language modeling tasks and 5 scene text recognition benchmarks demonstrate the effectiveness of our method.