 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Efficiency and Flexibility for DNN Acceleration via Temporal GPU-Systolic Array Integration
Paper and Code
Feb 18, 2020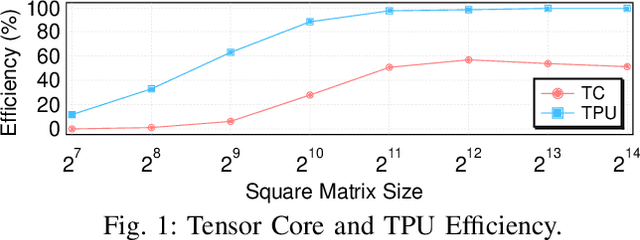
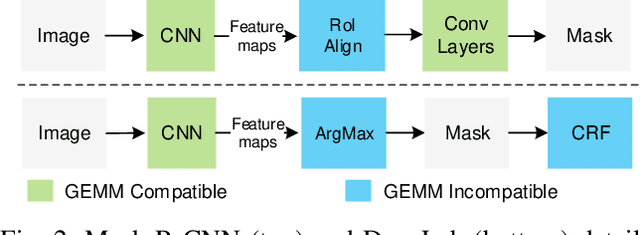

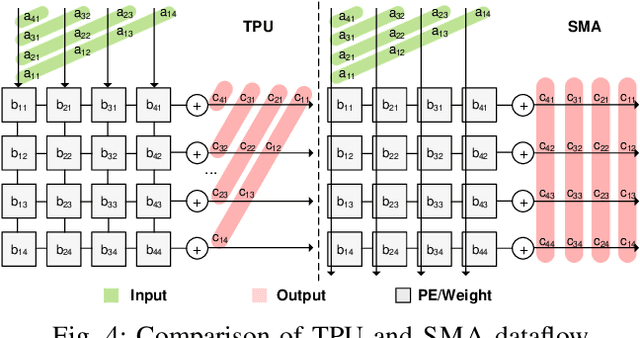
The research interest in specialized hardware accelerators for deep neural networks (DNN) spiked recently owing to their superior performance and efficiency. However, today's DNN accelerators primarily focus on accelerating specific "kernels" such as convolution and matrix multiplication, which are vital but only part of an end-to-end DNN-enabled application. Meaningful speedups over the entire application often require supporting computations that are, while massively parallel, ill-suited to DNN accelerators. Integrating a general-purpose processor such as a CPU or a GPU incurs significant data movement overhead and leads to resource under-utilization on the DNN accelerators. We propose Simultaneous Multi-mode Architecture (SMA), a novel architecture design and execution model that offers general-purpose programmability on DNN accelerators in order to accelerate end-to-end applications. The key to SMA is the temporal integration of the systolic execution model with the GPU-like SIMD execution model. The SMA exploits the common components shared between the systolic-array accelerator and the GPU, and provides lightweight reconfiguration capability to switch between the two modes in-situ. The SMA achieves up to 63% performance improvement while consuming 23% less energy than the baseline Volta architecture with TensorCore.