 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting
Paper and Code
Feb 17, 2020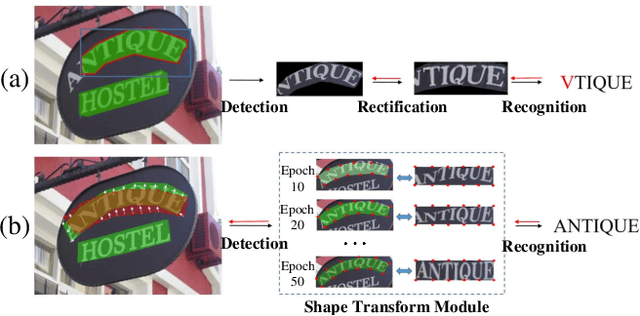
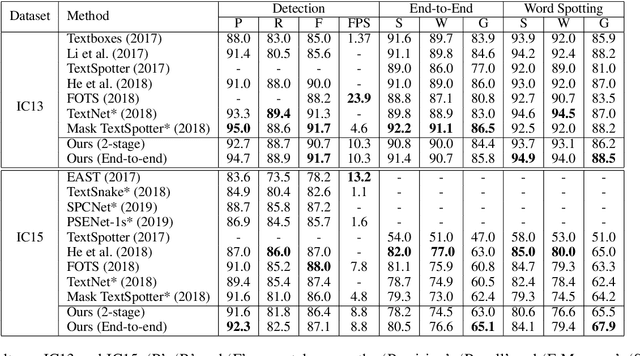
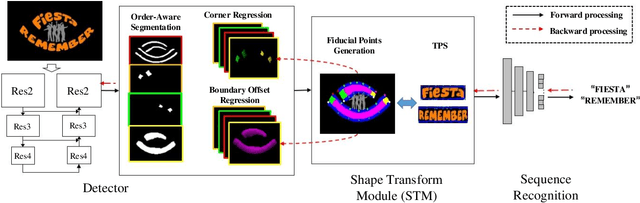
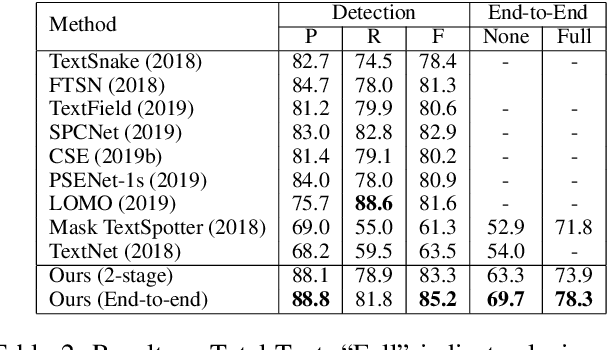
Many approaches have recently been proposed to detect irregular scene text and achieved promising results. However, their localization results may not well satisfy the following text recognition part mainly because of two reasons: 1) recognizing arbitrary shaped text is still a challenging task, and 2) prevalent non-trainable pipeline strategies between text detection and text recognition will lead to suboptimal performances. To handle this incompatibility problem, in this paper we propose an end-to-end trainable text spotting approach named Text Perceptron. Concretely, Text Perceptron first employs an efficient segmentation-based text detector that learns the latent text reading order and boundary information. Then a novel Shape Transform Module (abbr. STM) is designed to transform the detected feature regions into regular morphologies without extra parameters. It unites text detection and the following recognition part into a whole framework, and helps the whole network achieve global optimization. Experiments show that our method achieves competitive performance on two standard text benchmarks, i.e., ICDAR 2013 and ICDAR 2015, and also obviously outperforms existing methods on irregular text benchmarks SCUT-CTW1500 and Total-Text.