 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Task-Inference-Guided Deep Inverse Reinforcement Learning
Paper and Code
Jan 24, 2020


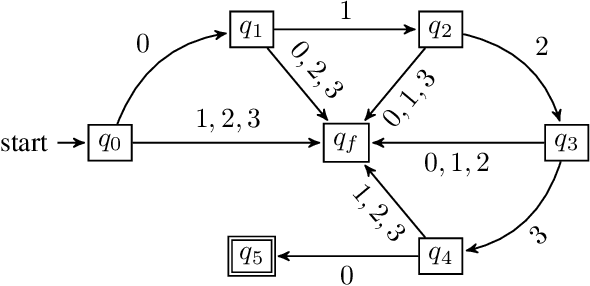
In inverse reinforcement learning (IRL), given a Markov decision process (MDP) and a set of demonstrations for completing a task, the objective is to learn a reward function to explain the demonstrations. However, it is challenging to apply IRL in tasks where a proper memory structure is the key to complete the task. To address this challenge, we develop an iterative algorithm that alternates between a task inference module that infers the high-level memory structure of the task and a reward learning module that learns a reward function with the inferred memory structure. In each iteration, the task inference module produces a series of queries to be answered by the demonstrator. Each query asks whether a sequence of high-level events leads to the completion of the task. The demonstrator then provides a demonstration executing the sequence to answer each query. After the queries are answered, the task inference module returns a hypothesis deterministic finite automaton (DFA) encoding the high-level memory structure to be used by the reward learning. The reward learning module incorporates the DFA states into the MDP states and creates a product automaton. Then the reward learning module proceeds to learn a Markovian reward function for this product automaton by performing deep maximum entropy IRL. At the end of each iteration, the algorithm computes an optimal policy with respect to the learned reward. This iterative process continues until the computed policy leads to satisfactory performance in completing the task. The experiments show that the proposed algorithm outperforms three IRL baselines in task performance.