 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead Beyond the Lines: Understanding the Implied Textual Meaning via a Skim and Intensive Reading Model
Paper and Code
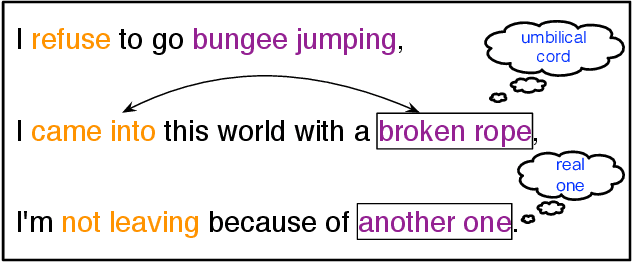
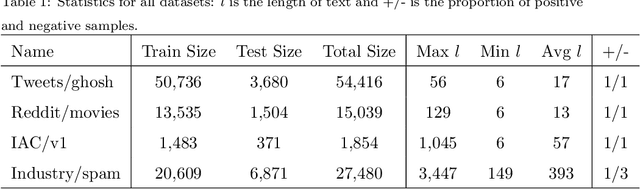
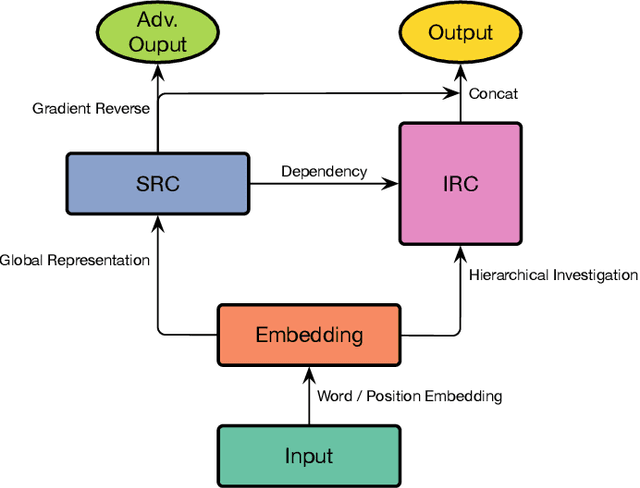
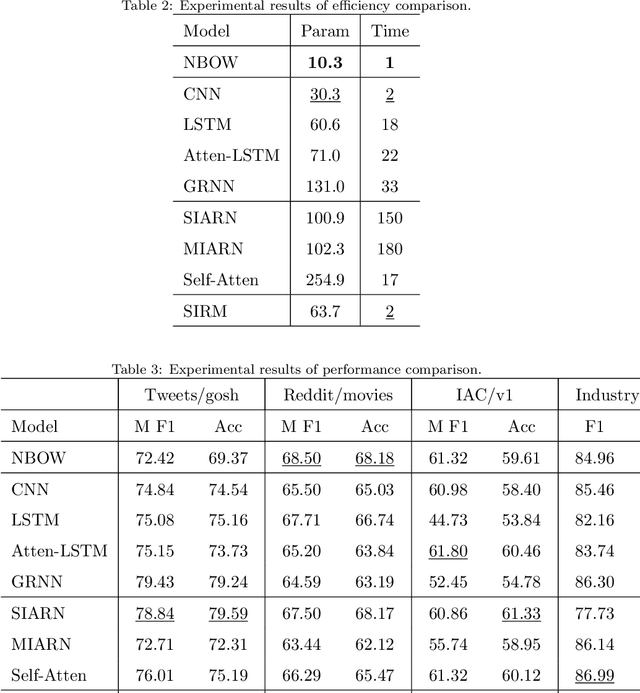
The nonliteral interpretation of a text is hard to be understood by machine models due to its high context-sensitivity and heavy usage of figurative language. In this study, inspired by human reading comprehension, we propose a novel, simple, and effective deep neural framework, called Skim and Intensive Reading Model (SIRM), for figuring out implied textual meaning. The proposed SIRM consists of two main components, namely the skim reading component and intensive reading component. N-gram features are quickly extracted from the skim reading component, which is a combination of several convolutional neural networks, as skim (entire) information. An intensive reading component enables a hierarchical investigation for both local (sentence) and global (paragraph) representation, which encapsulates the current embedding and the contextual information with a dense connection. More specifically, the contextual information includes the near-neighbor information and the skim information mentioned above. Finally, besides the normal training loss function, we employ an adversarial loss function as a penalty over the skim reading component to eliminate noisy information arisen from special figurative words in the training data. To verify the effectiveness, robustness, and efficiency of the proposed architecture, we conduct extensive comparative experiments on several sarcasm benchmarks and an industrial spam dataset with metaphors. Experimental results indicate that (1) the proposed model, which benefits from context modeling and consideration of figurative language, outperforms existing state-of-the-art solutions, with comparable parameter scale and training speed; (2) the SIRM yields superior robustness in terms of parameter size sensitivity; (3) compared with ablation and addition variants of the SIRM, the final framework is efficient enough.