 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion and Object based Panoptic Image Synthesis through Conditional GANs
Paper and Code
Dec 14, 2019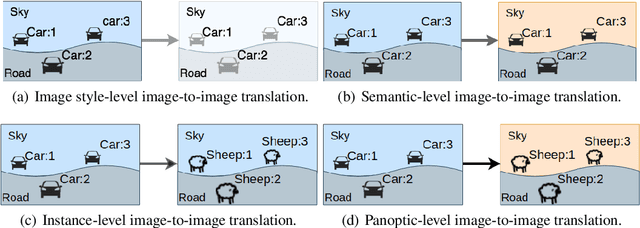
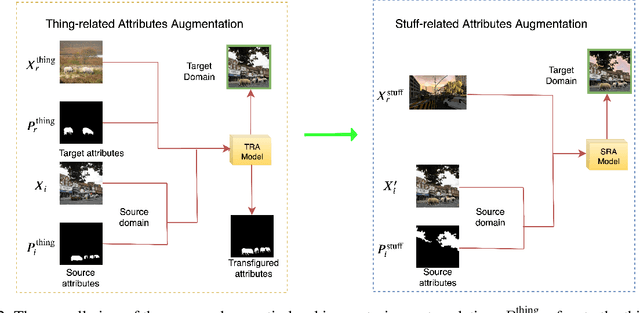
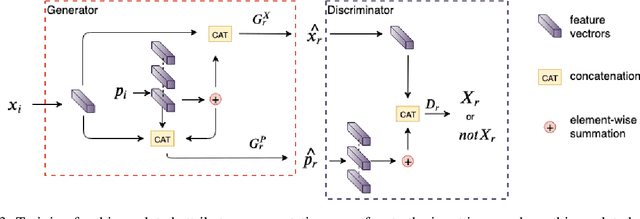
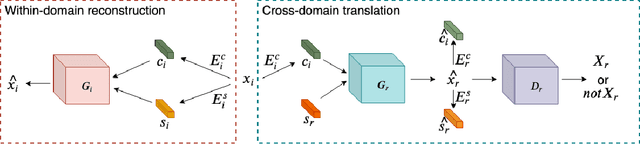
Image-to-image translation is significant to many computer vision and machine learning tasks such as image synthesis and video synthesis. It has primary applications in the graphics editing and animation industries. With the development of generative adversarial networks, a lot of attention has been drawn to image-to-image translation tasks. In this paper, we propose and investigate a novel task named as panoptic-level image-to-image translation and a naive baseline of solving this task. Panoptic-level image translation extends the current image translation task to two separate objectives of semantic style translation (adjust the style of objects to that of different domains) and instance transfiguration (swap between different types of objects). The proposed task generates an image from a complete and detailed panoptic perspective which can enrich the context of real-world vision synthesis. Our contribution consists of the proposal of a significant task worth investigating and a naive baseline of solving it. The proposed baseline consists of the multiple instances sequential translation and semantic-level translation with domain-invariant content code.