 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Robust Reinforcement Learning with Uncertainty-based Value Expansion
Paper and Code
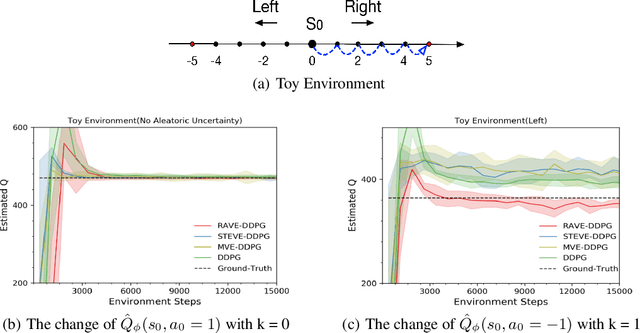
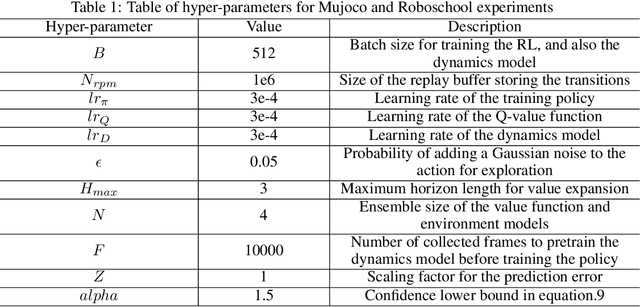
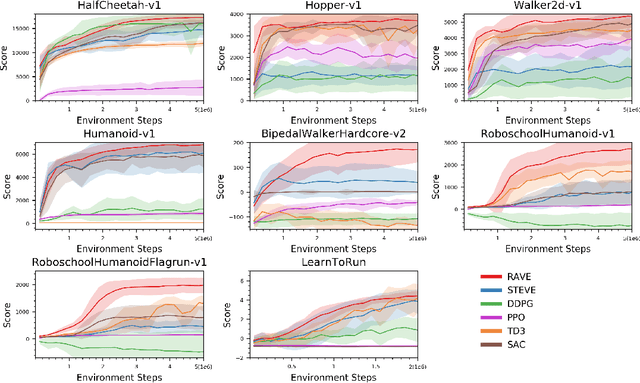
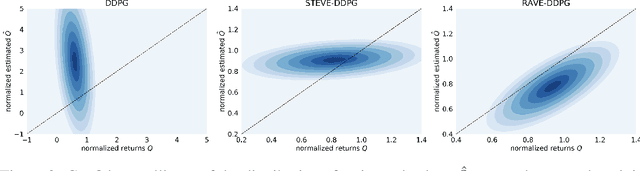
By integrating dynamics models into model-free reinforcement learning (RL) methods, model-based value expansion (MVE) algorithms have shown a significant advantage in sample efficiency as well as value estimation. However, these methods suffer from higher function approximation errors than model-free methods in stochastic environments due to a lack of modeling the environmental randomness. As a result, their performance lags behind the best model-free algorithms in some challenging scenarios. In this paper, we propose a novel Hybrid-RL method that builds on MVE, namely the Risk Averse Value Expansion (RAVE). With imaginative rollouts generated by an ensemble of probabilistic dynamics models, we further introduce the aversion of risks by seeking the lower confidence bound of the estimation. Experiments on a range of challenging environments show that by modeling the uncertainty completely, RAVE substantially enhances the robustness of previous model-based methods, and yields state-of-the-art performance. With this technique, our solution gets the first place in NeurIPS 2019: Learn to Move.