 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextSLAM: Visual SLAM with Planar Text Features
Paper and Code
Nov 26, 2019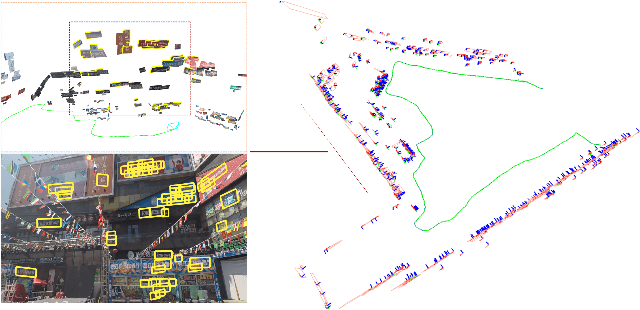
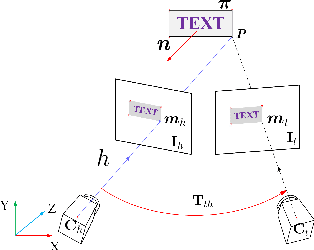
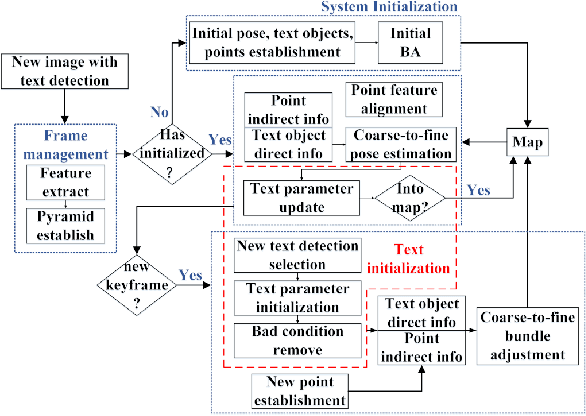

We propose to integrate text objects in man-made scenes tightly into the visual SLAM pipeline. The key idea of our novel text-based visual SLAM is to treat each detected text as a planar feature which is rich of textures and semantic meanings. The text feature is compactly represented by three parameters and integrated into visual SLAM by adopting the illumination-invariant photometric error. We also describe important details involved in implementing a full pipeline of text-based visual SLAM. To our best knowledge, this is the first visual SLAM method tightly coupled with the text features. We tested our method in both indoor and outdoor environments. The results show that with text features, the visual SLAM system becomes more robust and produces much more accurate 3D text maps that could be useful for navigation and scene understanding in robotic or augmented reality applications.