 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic and Dynamic Fusion for Multi-modal Cross-ethnicity Face Anti-spoofing
Paper and Code
Dec 16, 2019
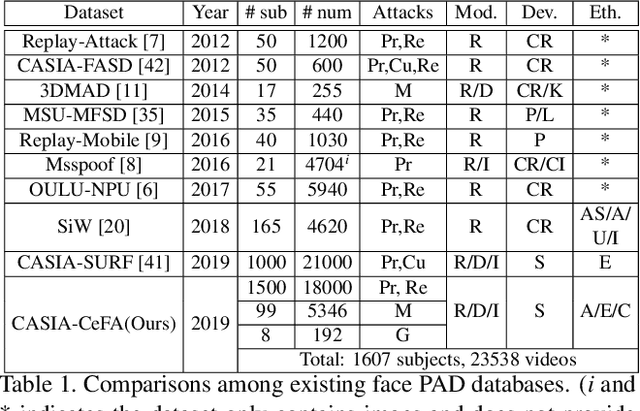
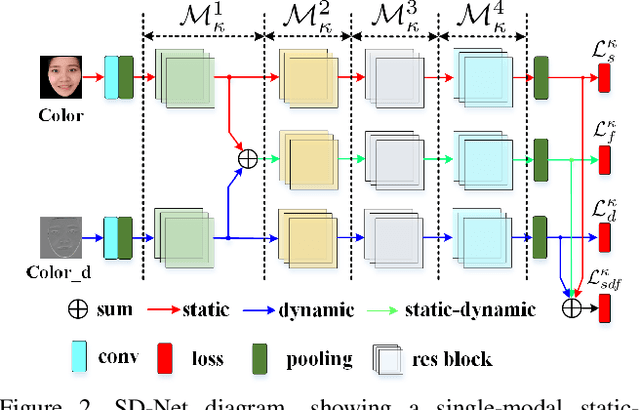
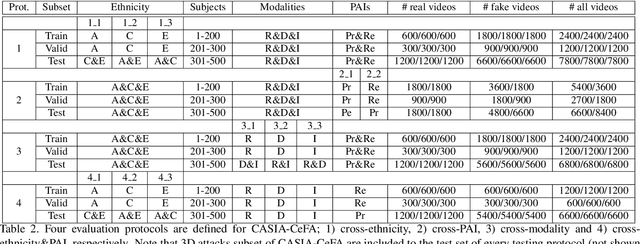
Regardless of the usage of deep learning and handcrafted methods, the dynamic information from videos and the effect of cross-ethnicity are rarely considered in face anti-spoofing. In this work, we propose a static-dynamic fusion mechanism for multi-modal face anti-spoofing. Inspired by motion divergences between real and fake faces, we incorporate the dynamic image calculated by rank pooling with static information into a conventional neural network (CNN) for each modality (i.e., RGB, Depth and infrared (IR)). Then, we develop a partially shared fusion method to learn complementary information from multiple modalities. Furthermore, in order to study the generalization capability of the proposal in terms of cross-ethnicity attacks and unknown spoofs, we introduce the largest public cross-ethnicity Face Anti-spoofing (CASIA-CeFA) dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 2D plus 3D attack types. Experiments demonstrate that the proposed method achieves state-of-the-art results on CASIA-CeFA, CASIA-SURF, OULU-NPU and SiW.