 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepGoal: Learning to Drive with driving intention from Human Control Demonstration
Paper and Code
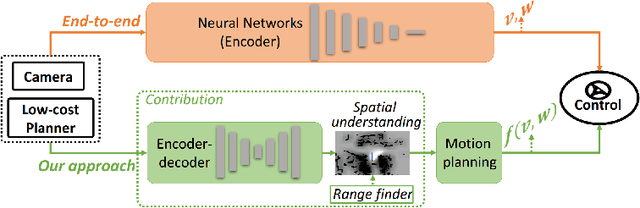

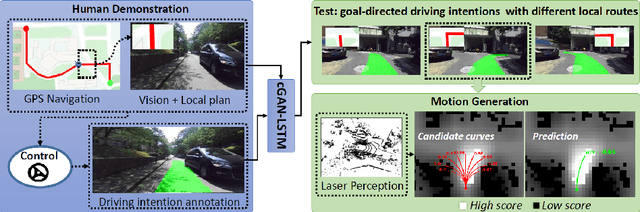
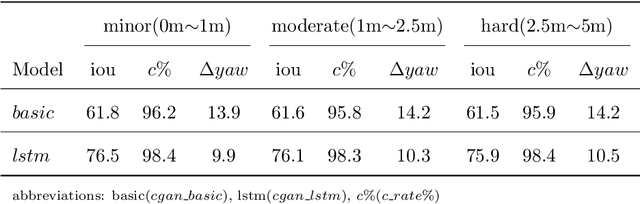
Recent research on automotive driving developed an efficient end-to-end learning mode that directly maps visual input to control commands. However, it models distinct driving variations in a single network, which increases learning complexity and is less adaptive for modular integration. In this paper, we re-investigate human's driving style and propose to learn an intermediate driving intention region to relax difficulties in end-to-end approach. The intention region follows both road structure in image and direction towards goal in public route planner, which addresses visual variations only and figures out where to go without conventional precise localization. Then the learned visual intention is projected on vehicle local coordinate and fused with reliable obstacle perception to render a navigation score map widely used for motion planning. The core of the proposed system is a weakly-supervised cGAN-LSTM model trained to learn driving intention from human demonstration. The adversarial loss learns from limited demonstration data with one local planned route and enables reasoning of multi-modal behavior with diverse routes while testing. Comprehensive experiments are conducted with real-world datasets. Results show the proposed paradigm can produce more consistent motion commands with human demonstration, and indicates better reliability and robustness to environment change.