 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeRoP: A Learning-Based Modular Robot Photography Framework
Paper and Code
Nov 28, 2019
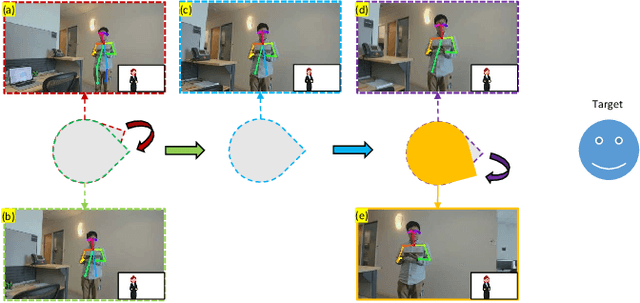

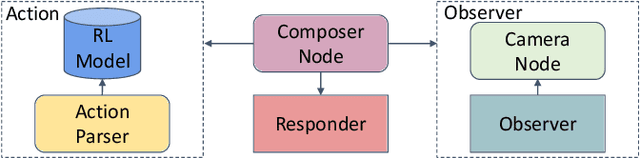
We introduce a novel framework for automatic capturing of human portraits. The framework allows the robot to follow a person to the desired location using a Person Re-identification model. When composing is activated, the robot attempts to adjust its position to form the view that can best match the given template image, and finally takes a photograph. A template image can be predicted dynamically using an off-the-shelf photo evaluation model by the framework, or selected manually from a pre-defined set by the user. The template matching-based view adjustment is driven by a deep reinforcement learning network. Our framework lies on top of the Robot Operating System (ROS). The framework is designed to be modular so that all the models can be flexibly replaced based on needs. We show our framework on a variety of examples. In particular, we tested it in three indoor scenes and used it to take 20 photos of each scene: ten for the pre-defined template, ten for the dynamically generated ones. The average number of adjustment was $11.20$ for pre-defined templates and $12.76$ for dynamically generated ones; the average time spent was $22.11$ and $24.10$ seconds respectively.