 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-source Distilling Domain Adaptation
Paper and Code
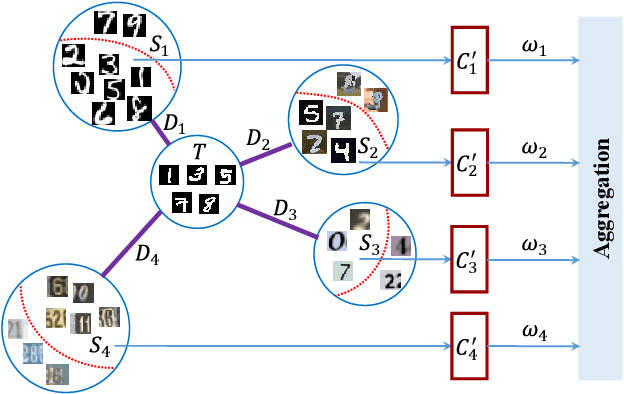
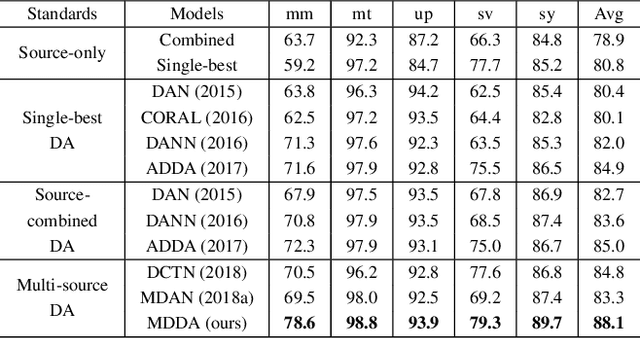
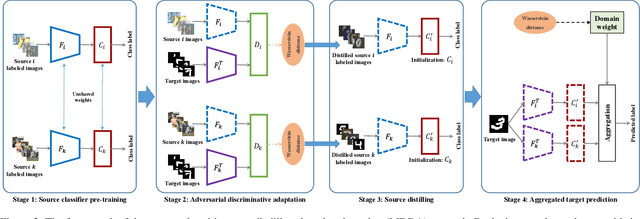
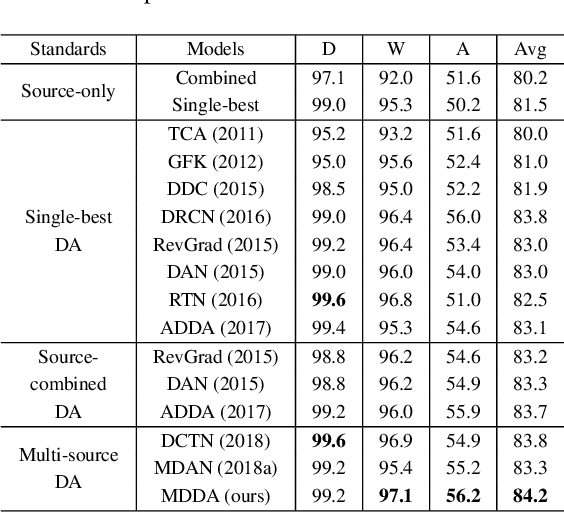
Deep neural networks suffer from performance decay when there is domain shift between the labeled source domain and unlabeled target domain, which motivates the research on domain adaptation (DA). Conventional DA methods usually assume that the labeled data is sampled from a single source distribution. However, in practice, labeled data may be collected from multiple sources, while naive application of the single-source DA algorithms may lead to suboptimal solutions. In this paper, we propose a novel multi-source distilling domain adaptation (MDDA) network, which not only considers the different distances among multiple sources and the target, but also investigates the different similarities of the source samples to the target ones. Specifically, the proposed MDDA includes four stages: (1) pre-train the source classifiers separately using the training data from each source; (2) adversarially map the target into the feature space of each source respectively by minimizing the empirical Wasserstein distance between source and target; (3) select the source training samples that are closer to the target to fine-tune the source classifiers; and (4) classify each encoded target feature by corresponding source classifier, and aggregate different predictions using respective domain weight, which corresponds to the discrepancy between each source and target. Extensive experiments are conducted on public DA benchmarks, and the results demonstrate that the proposed MDDA significantly outperforms the state-of-the-art approaches. Our source code is released at: https://github.com/daoyuan98/MDDA.