 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelized Multiview Subspace Analysis by Self-weighted Learning
Paper and Code
Nov 23, 2019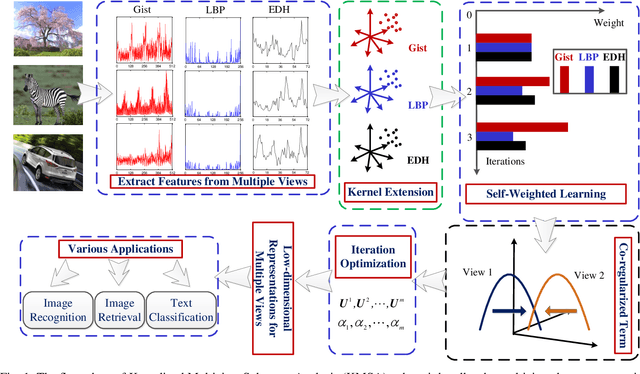
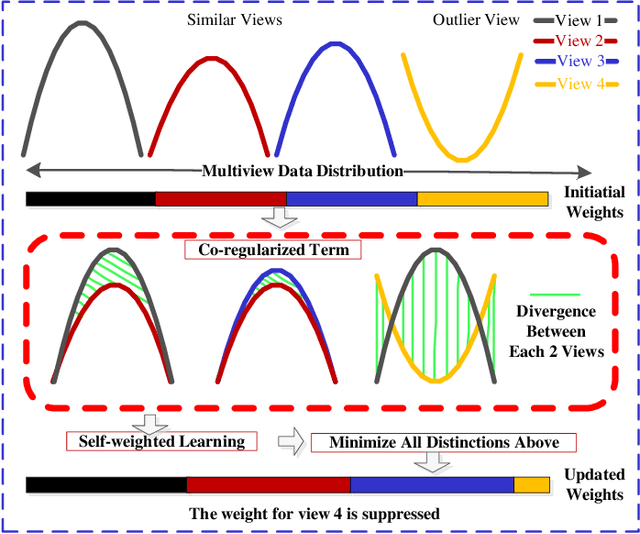
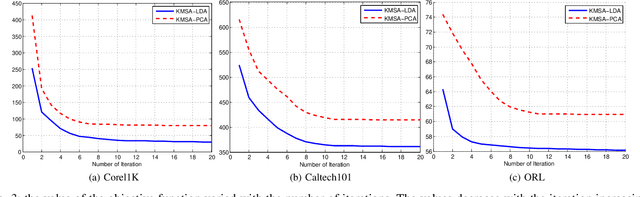

With the popularity of multimedia technology, information is always represented or transmitted from multiple views. Most of the existing algorithms are graph-based ones to learn the complex structures within multiview data but overlooked the information within data representations. Furthermore, many existing works treat multiple views discriminatively by introducing some hyperparameters, which is undesirable in practice. To this end, abundant multiview based methods have been proposed for dimension reduction. However, there are still no research to leverage the existing work into a unified framework. To address this issue, in this paper, we propose a general framework for multiview data dimension reduction, named Kernelized Multiview Subspace Analysis (KMSA). It directly handles the multi-view feature representation in the kernel space, which provides a feasible channel for direct manipulations on multiview data with different dimensions. Meanwhile, compared with those graph-based methods, KMSA can fully exploit information from multiview data with nothing to lose. Furthermore, since different views have different influences on KMSA, we propose a self-weighted strategy to treat different views discriminatively according to their contributions. A co-regularized term is proposed to promote the mutual learning from multi-views. KMSA combines self-weighted learning with the co-regularized term to learn appropriate weights for all views. We also discuss the influence of the parameters in KMSA regarding the weights of multi-views. We evaluate our proposed framework on 6 multiview datasets for classification and image retrieval. The experimental results validate the advantages of our proposed method.