 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Video Moment Retrieval via Semantic Completion Network
Paper and Code
Nov 19, 2019
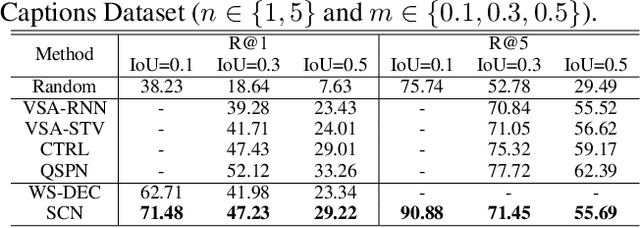
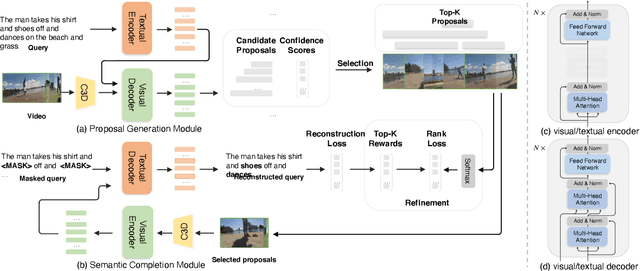
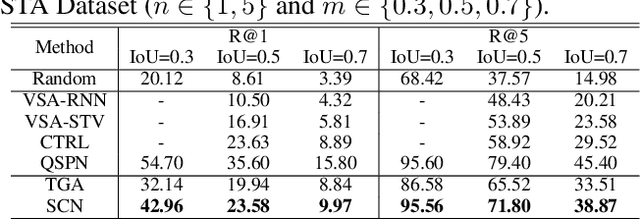
Video moment retrieval is to search the moment that is most relevant to the given natural language query. Existing methods are mostly trained in a fully-supervised setting, which requires the full annotations of temporal boundary for each query. However, manually labeling the annotations is actually time-consuming and expensive. In this paper, we propose a novel weakly-supervised moment retrieval framework requiring only coarse video-level annotations for training. Specifically, we devise a proposal generation module that aggregates the context information to generate and score all candidate proposals in one single pass. We then devise an algorithm that considers both exploitation and exploration to select top-K proposals. Next, we build a semantic completion module to measure the semantic similarity between the selected proposals and query, compute reward and provide feedbacks to the proposal generation module for scoring refinement. Experiments on the ActivityCaptions and Charades-STA demonstrate the effectiveness of our proposed method.