 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Multilingual Neural Machine Translation to Unseen Languages
Paper and Code
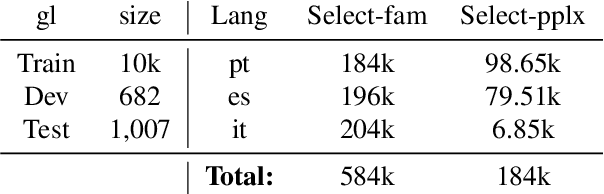
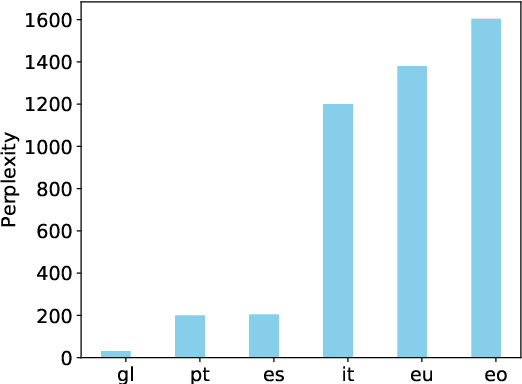
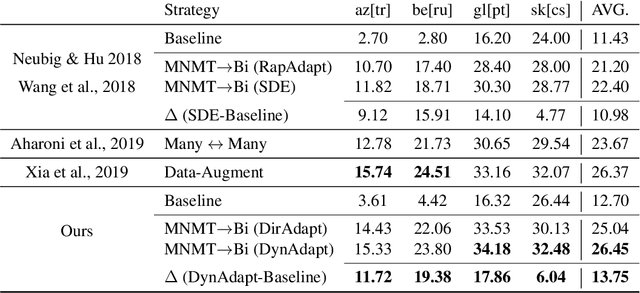
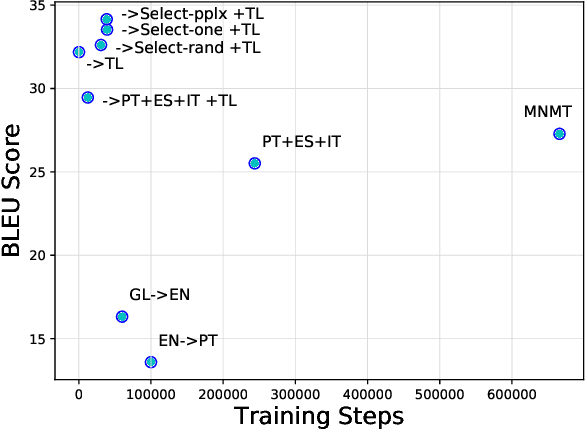
Multilingual Neural Machine Translation (MNMT) for low-resource languages (LRL) can be enhanced by the presence of related high-resource languages (HRL), but the relatedness of HRL usually relies on predefined linguistic assumptions about language similarity. Recently, adapting MNMT to a LRL has shown to greatly improve performance. In this work, we explore the problem of adapting an MNMT model to an unseen LRL using data selection and model adaptation. In order to improve NMT for LRL, we employ perplexity to select HRL data that are most similar to the LRL on the basis of language distance. We extensively explore data selection in popular multilingual NMT settings, namely in (zero-shot) translation, and in adaptation from a multilingual pre-trained model, for both directions (LRL-en). We further show that dynamic adaptation of the model's vocabulary results in a more favourable segmentation for the LRL in comparison with direct adaptation. Experiments show reductions in training time and significant performance gains over LRL baselines, even with zero LRL data (+13.0 BLEU), up to +17.0 BLEU for pre-trained multilingual model dynamic adaptation with related data selection. Our method outperforms current approaches, such as massively multilingual models and data augmentation, on four LRL.