 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Control with Contexts, Provably
Paper and Code
Oct 30, 2019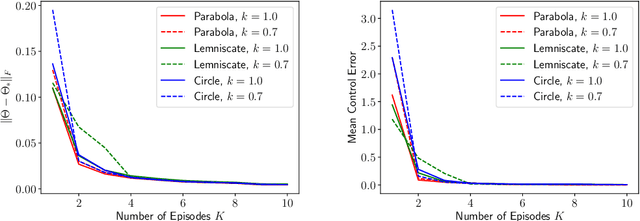
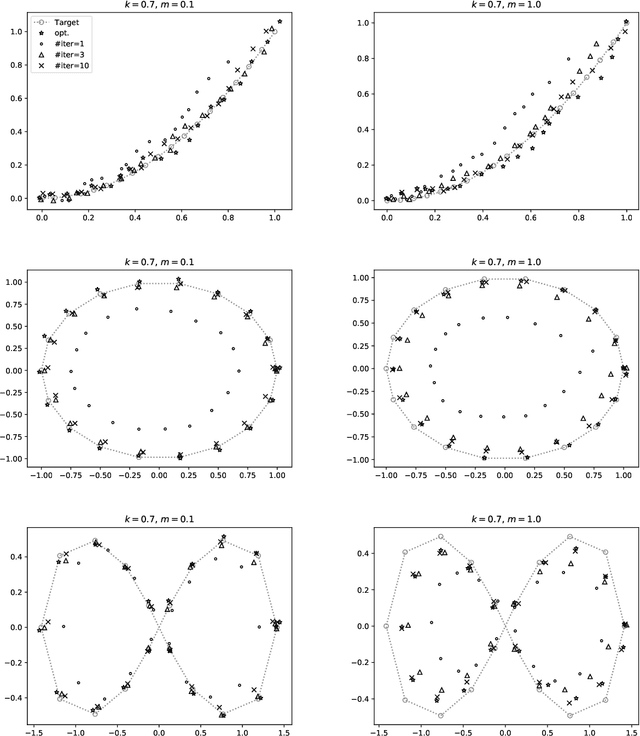
A fundamental challenge in artificial intelligence is to build an agent that generalizes and adapts to unseen environments. A common strategy is to build a decoder that takes the context of the unseen new environment as input and generates a policy accordingly. The current paper studies how to build a decoder for the fundamental continuous control task, linear quadratic regulator (LQR), which can model a wide range of real-world physical environments. We present a simple algorithm for this problem, which uses upper confidence bound (UCB) to refine the estimate of the decoder and balance the exploration-exploitation trade-off. Theoretically, our algorithm enjoys a $\widetilde{O}\left(\sqrt{T}\right)$ regret bound in the online setting where $T$ is the number of environments the agent played. This also implies after playing $\widetilde{O}\left(1/\epsilon^2\right)$ environments, the agent is able to transfer the learned knowledge to obtain an $\epsilon$-suboptimal policy for an unseen environment. To our knowledge, this is first provably efficient algorithm to build a decoder in the continuous control setting. While our main focus is theoretical, we also present experiments that demonstrate the effectiveness of our algorithm.