 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyphrase Extraction from Scholarly Articles as Sequence Labeling using Contextualized Embeddings
Paper and Code
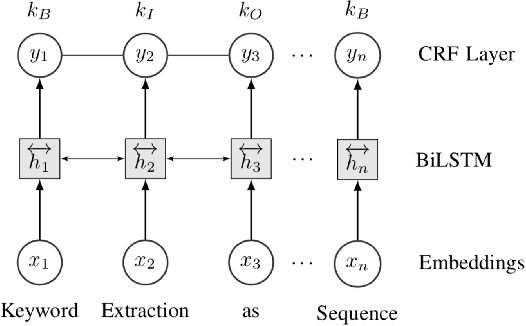
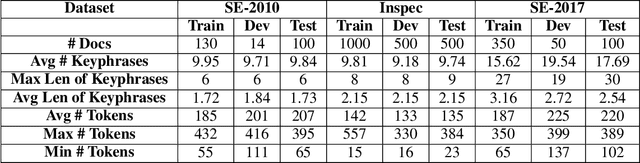
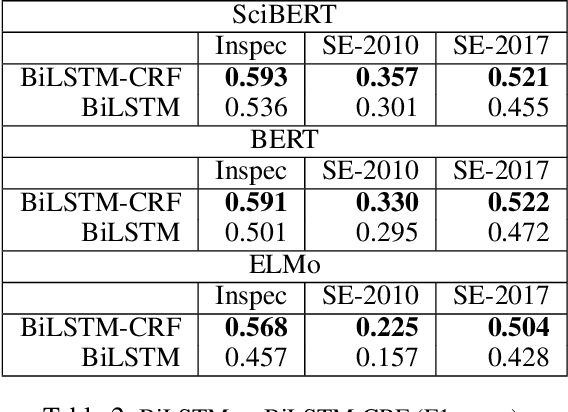
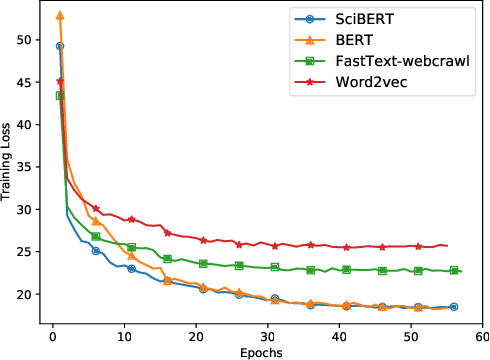
In this paper, we formulate keyphrase extraction from scholarly articles as a sequence labeling task solved using a BiLSTM-CRF, where the words in the input text are represented using deep contextualized embeddings. We evaluate the proposed architecture using both contextualized and fixed word embedding models on three different benchmark datasets (Inspec, SemEval 2010, SemEval 2017) and compare with existing popular unsupervised and supervised techniques. Our results quantify the benefits of (a) using contextualized embeddings (e.g. BERT) over fixed word embeddings (e.g. Glove); (b) using a BiLSTM-CRF architecture with contextualized word embeddings over fine-tuning the contextualized word embedding model directly, and (c) using genre-specific contextualized embeddings (SciBERT). Through error analysis, we also provide some insights into why particular models work better than others. Lastly, we present a case study where we analyze different self-attention layers of the two best models (BERT and SciBERT) to better understand the predictions made by each for the task of keyphrase extraction.