 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagined Value Gradients: Model-Based Policy Optimization with Transferable Latent Dynamics Models
Paper and Code
Oct 09, 2019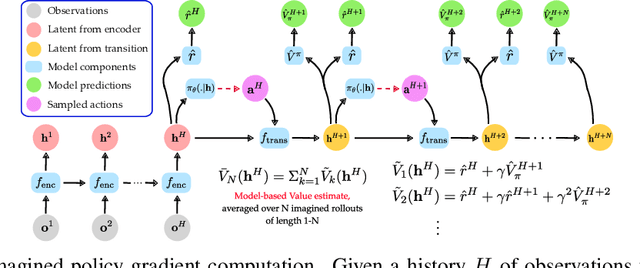



Humans are masters at quickly learning many complex tasks, relying on an approximate understanding of the dynamics of their environments. In much the same way, we would like our learning agents to quickly adapt to new tasks. In this paper, we explore how model-based Reinforcement Learning (RL) can facilitate transfer to new tasks. We develop an algorithm that learns an action-conditional, predictive model of expected future observations, rewards and values from which a policy can be derived by following the gradient of the estimated value along imagined trajectories. We show how robust policy optimization can be achieved in robot manipulation tasks even with approximate models that are learned directly from vision and proprioception. We evaluate the efficacy of our approach in a transfer learning scenario, re-using previously learned models on tasks with different reward structures and visual distractors, and show a significant improvement in learning speed compared to strong off-policy baselines. Videos with results can be found at https://sites.google.com/view/ivg-corl19