 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Low-Dimensional Structures in Markov Chains: A Nonnegative Matrix Factorization Approach
Paper and Code
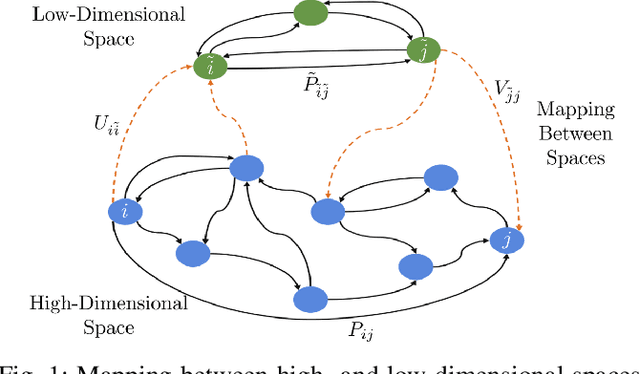
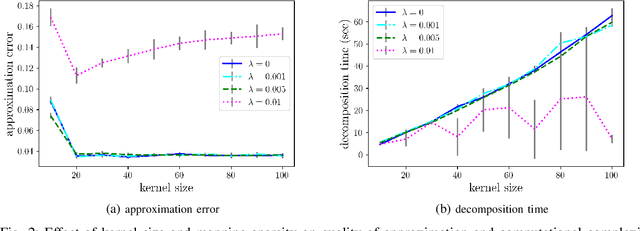
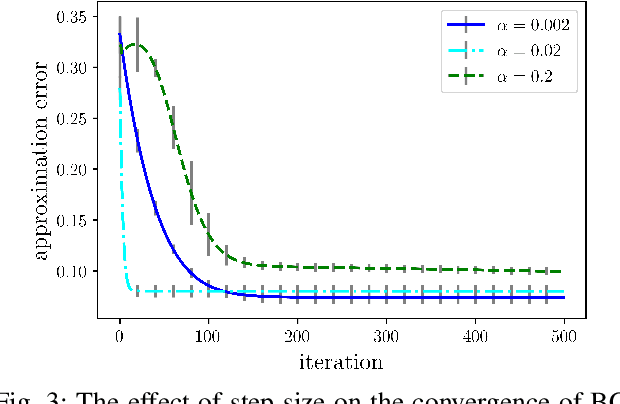
A variety of queries about stochastic systems boil down to study of Markov chains and their properties. If the Markov chain is large, as is typically true for discretized continuous spaces, such analysis may be computationally intractable. Nevertheless, in many scenarios, Markov chains have underlying structural properties that allow them to admit a low-dimensional representation. For instance, the transition matrix associated with the model may be low-rank and hence, representable in a lower-dimensional space. We consider the problem of learning low-dimensional representations for large-scale Markov chains. To that end, we formulate the task of representation learning as that of mapping the state space of the model to a low-dimensional state space, referred to as the kernel space. The kernel space contains a set of meta states which are desired to be representative of only a small subset of original states. To promote this structural property, we constrain the number of nonzero entries of the mappings between the state space and the kernel space. By imposing the desired characteristics of the structured representation, we cast the problem as the task of nonnegative matrix factorization. To compute the solution, we propose an efficient block coordinate gradient descent and theoretically analyze its convergence properties. Our extensive simulation results demonstrate the efficacy of the proposed algorithm in terms of the quality of the low-dimensional representation as well as its computational cost.