 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Natural Language Generation via Pre-Training
Paper and Code
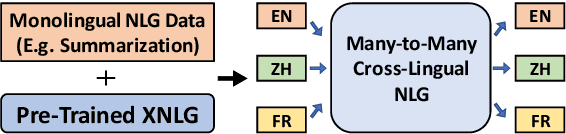
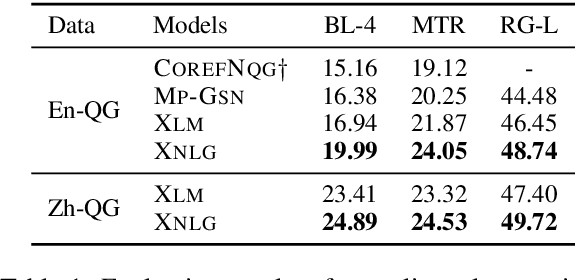
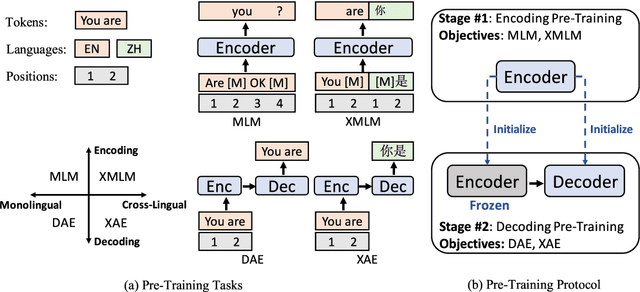
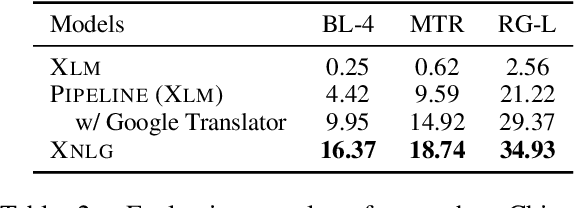
In this work we focus on transferring supervision signals of natural language generation (NLG) tasks between multiple languages. We propose to pretrain the encoder and decoder of a sequence-to-sequence model under both monolingual and cross-lingual settings. The pre-training objective encourages the model to represent different languages in the shared space, so that we can conduct zero-shot cross-lingual transfer. After the pre-training procedure, we use monolingual data to fine-tune the pre-trained model on downstream NLG tasks. Then the sequence-to-sequence model trained in a single language can be directly evaluated beyond that language (i.e., accepting multi-lingual input and producing multi-lingual output). Experimental results on question generation and abstractive summarization show that our model outperforms the machine-translation-based pipeline methods for zero-shot cross-lingual generation. Moreover, cross-lingual transfer improves NLG performance of low-resource languages by leveraging rich-resource language data.