 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Center FPGA Acceleration Platform for Convolutional Neural Networks
Paper and Code
Sep 17, 2019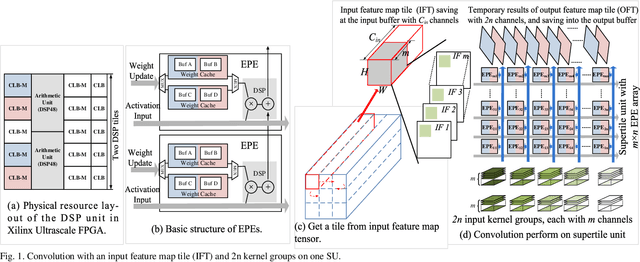
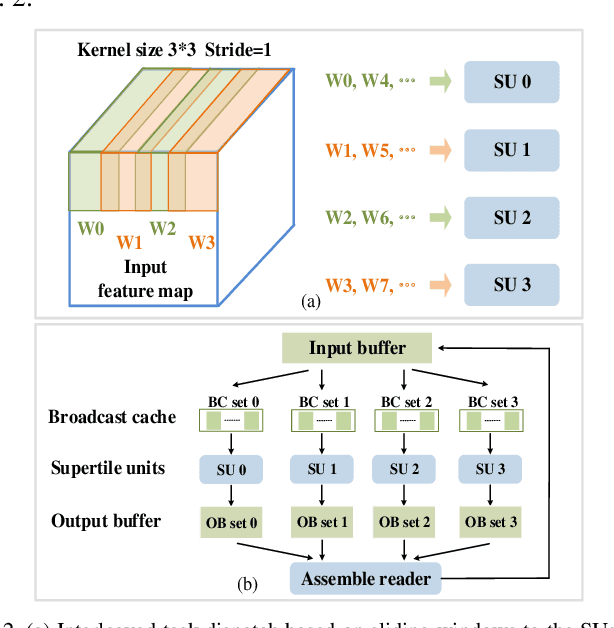
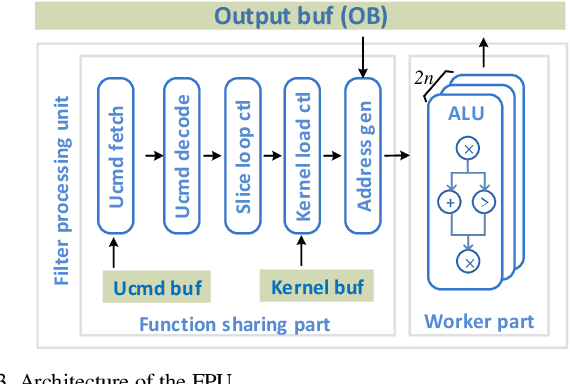
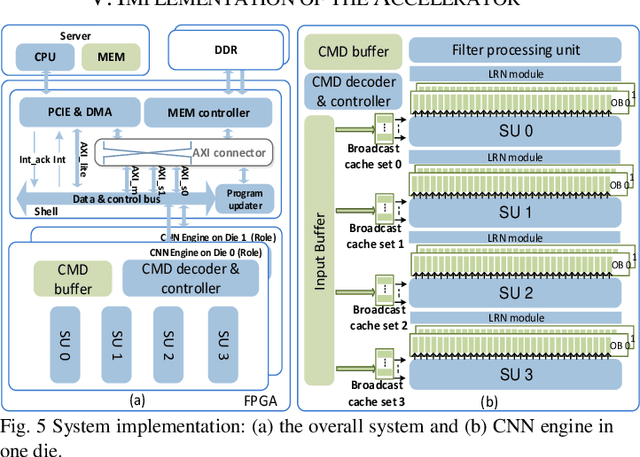
Intensive computation is entering data centers with multiple workloads of deep learning. To balance the compute efficiency, performance, and total cost of ownership (TCO), the use of a field-programmable gate array (FPGA) with reconfigurable logic provides an acceptable acceleration capacity and is compatible with diverse computation-sensitive tasks in the cloud. In this paper, we develop an FPGA acceleration platform that leverages a unified framework architecture for general-purpose convolutional neural network (CNN) inference acceleration at a data center. To overcome the computation bound, 4,096 DSPs are assembled and shaped as supertile units (SUs) for different types of convolution, which provide up to 4.2 TOP/s 16-bit fixed-point performance at 500 MHz. The interleaved-task-dispatching method is proposed to map the computation across the SUs, and the memory bound is solved by a dispatching-assembling buffering model and broadcast caches. For various non-convolution operators, a filter processing unit is designed for general-purpose filter-like/pointwise operators. In the experiment, the performances of CNN models running on server-class CPUs, a GPU, and an FPGA are compared. The results show that our design achieves the best FPGA peak performance and a throughput at the same level as that of the state-of-the-art GPU in data centers, with more than 50 times lower latency.