 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Alignment for Multimodal Emotion Recognition from Speech
Paper and Code
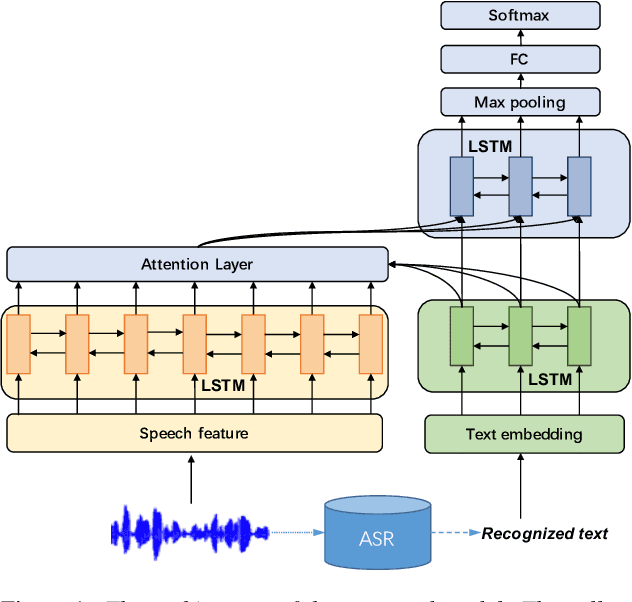
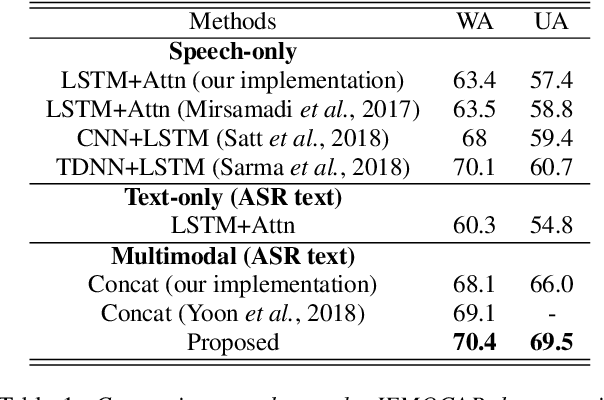
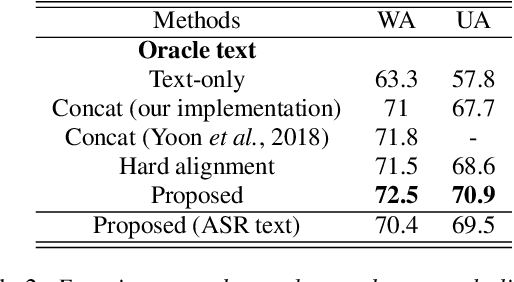
Speech emotion recognition is a challenging problem because human convey emotions in subtle and complex ways. For emotion recognition on human speech, one can either extract emotion related features from audio signals or employ speech recognition techniques to generate text from speech and then apply natural language processing to analyze the sentiment. Further, emotion recognition will be beneficial from using audio-textual multimodal information, it is not trivial to build a system to learn from multimodality. One can build models for two input sources separately and combine them in a decision level, but this method ignores the interaction between speech and text in the temporal domain. In this paper, we propose to use an attention mechanism to learn the alignment between speech frames and text words, aiming to produce more accurate multimodal feature representations. The aligned multimodal features are fed into a sequential model for emotion recognition. We evaluate the approach on the IEMOCAP dataset and the experimental results show the proposed approach achieves the state-of-the-art performance on the dataset.