 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAC-Teach: A Bayesian Actor-Critic Method for Policy Learning with an Ensemble of Suboptimal Teachers
Paper and Code
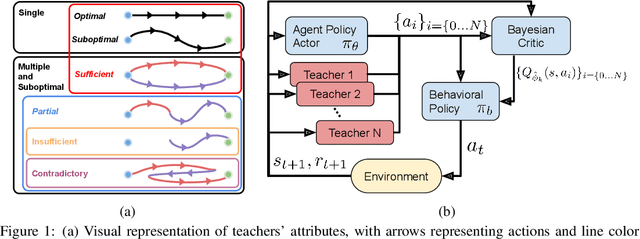

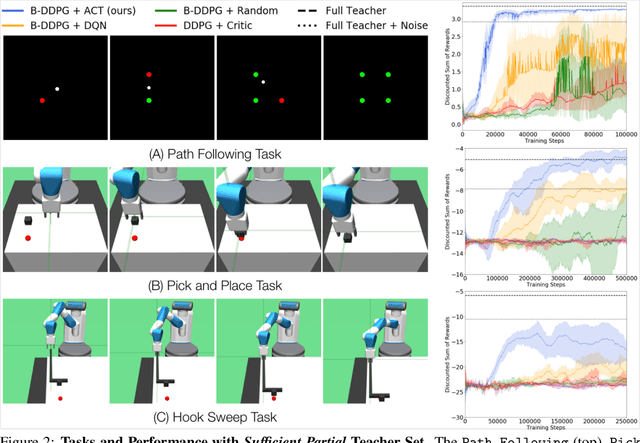
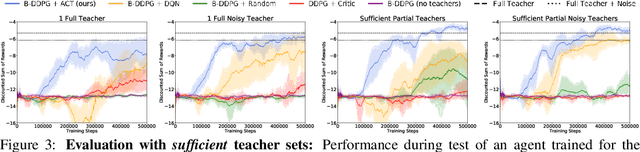
The exploration mechanism used by a Deep Reinforcement Learning (RL) agent plays a key role in determining its sample efficiency. Thus, improving over random exploration is crucial to solve long-horizon tasks with sparse rewards. We propose to leverage an ensemble of partial solutions as teachers that guide the agent's exploration with action suggestions throughout training. While the setup of learning with teachers has been previously studied, our proposed approach - Actor-Critic with Teacher Ensembles (AC-Teach) - is the first to work with an ensemble of suboptimal teachers that may solve only part of the problem or contradict other each other, forming a unified algorithmic solution that is compatible with a broad range of teacher ensembles. AC-Teach leverages a probabilistic representation of the expected outcome of the teachers' and student's actions to direct exploration, reduce dithering, and adapt to the dynamically changing quality of the learner. We evaluate a variant of AC-Teach that guides the learning of a Bayesian DDPG agent on three tasks - path following, robotic pick and place, and robotic cube sweeping using a hook - and show that it improves largely on sampling efficiency over a set of baselines, both for our target scenario of unconstrained suboptimal teachers and for easier setups with optimal or single teachers. Additional results and videos at https://sites.google.com/view/acteach/home.