 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacet-Aware Evaluation for Extractive Text Summarization
Paper and Code

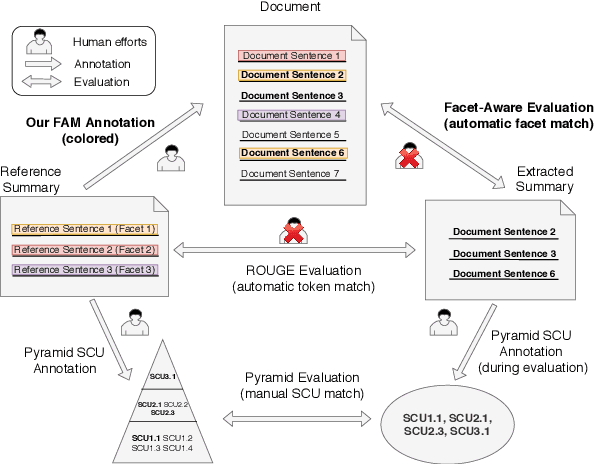

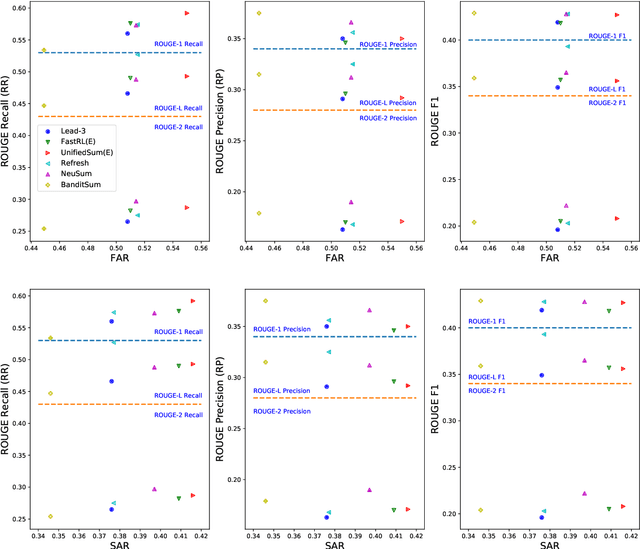
Commonly adopted metrics for extractive text summarization like ROUGE focus on the lexical similarity and are facet-agnostic. In this paper, we present a facet-aware evaluation procedure for better assessment of the information coverage in extracted summaries while still supporting automatic evaluation once annotated. Specifically, we treat \textit{facet} instead of \textit{token} as the basic unit for evaluation, manually annotate the \textit{support sentences} for each facet, and directly evaluate extractive methods by comparing the indices of extracted sentences with support sentences. We demonstrate the benefits of the proposed setup by performing a thorough \textit{quantitative} investigation on the CNN/Daily Mail dataset, which in the meantime reveals useful insights of state-of-the-art summarization methods.\footnote{Data can be found at \url{https://github.com/morningmoni/FAR}.