 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Neural Machine Translation with Language Clustering
Paper and Code
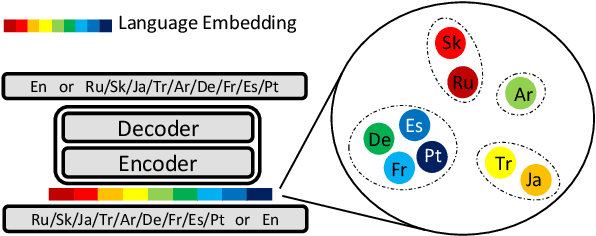
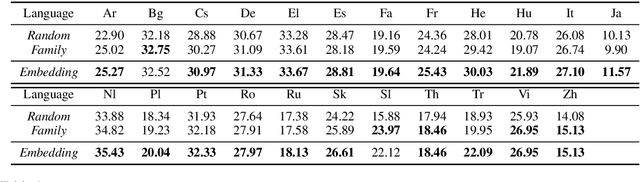
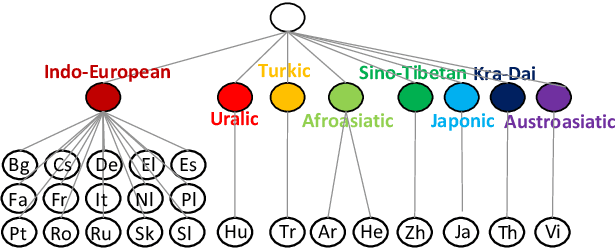
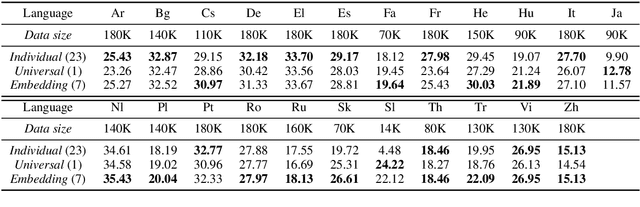
Multilingual neural machine translation (NMT), which translates multiple languages using a single model, is of great practical importance due to its advantages in simplifying the training process, reducing online maintenance costs, and enhancing low-resource and zero-shot translation. Given there are thousands of languages in the world and some of them are very different, it is extremely burdensome to handle them all in a single model or use a separate model for each language pair. Therefore, given a fixed resource budget, e.g., the number of models, how to determine which languages should be supported by one model is critical to multilingual NMT, which, unfortunately, has been ignored by previous work. In this work, we develop a framework that clusters languages into different groups and trains one multilingual model for each cluster. We study two methods for language clustering: (1) using prior knowledge, where we cluster languages according to language family, and (2) using language embedding, in which we represent each language by an embedding vector and cluster them in the embedding space. In particular, we obtain the embedding vectors of all the languages by training a universal neural machine translation model. Our experiments on 23 languages show that the first clustering method is simple and easy to understand but leading to suboptimal translation accuracy, while the second method sufficiently captures the relationship among languages well and improves the translation accuracy for almost all the languages over baseline methods