 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Outfit Recommendation with Co-supervision of Fashion Generation
Paper and Code
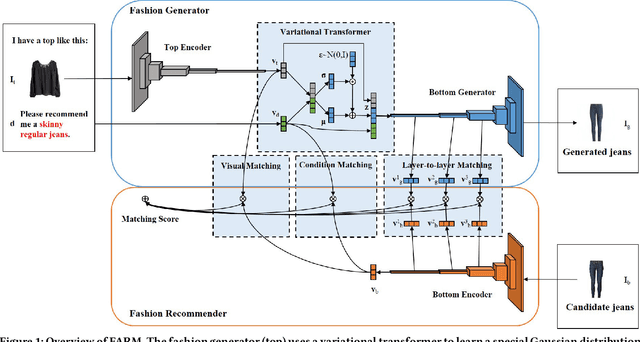
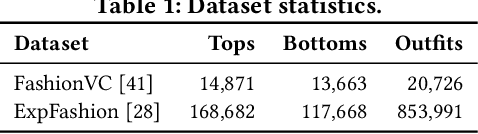
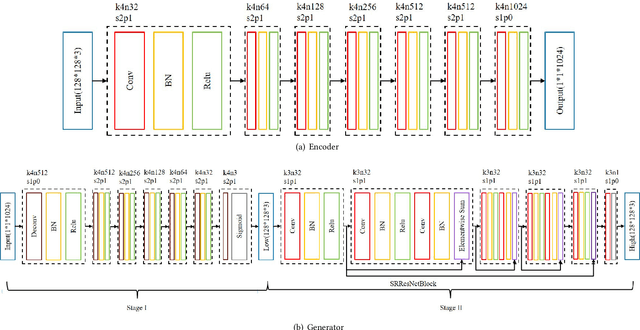
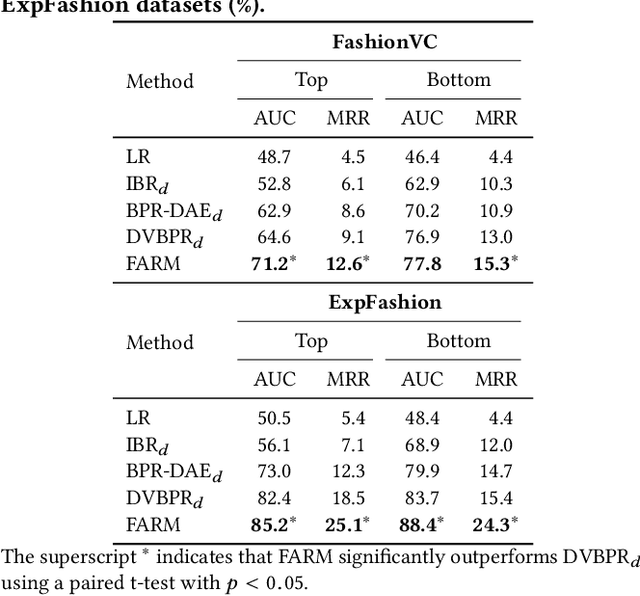
The task of fashion recommendation includes two main challenges: visual understanding and visual matching. Visual understanding aims to extract effective visual features. Visual matching aims to model a human notion of compatibility to compute a match between fashion items. Most previous studies rely on recommendation loss alone to guide visual understanding and matching. Although the features captured by these methods describe basic characteristics (e.g., color, texture, shape) of the input items, they are not directly related to the visual signals of the output items (to be recommended). This is problematic because the aesthetic characteristics (e.g., style, design), based on which we can directly infer the output items, are lacking. Features are learned under the recommendation loss alone, where the supervision signal is simply whether the given two items are matched or not. To address this problem, we propose a neural co-supervision learning framework, called the FAshion Recommendation Machine (FARM). FARM improves visual understanding by incorporating the supervision of generation loss, which we hypothesize to be able to better encode aesthetic information. FARM enhances visual matching by introducing a novel layer-to-layer matching mechanism to fuse aesthetic information more effectively, and meanwhile avoiding paying too much attention to the generation quality and ignoring the recommendation performance. Extensive experiments on two publicly available datasets show that FARM outperforms state-of-the-art models on outfit recommendation, in terms of AUC and MRR. Detailed analyses of generated and recommended items demonstrate that FARM can encode better features and generate high quality images as references to improve recommendation performance.