 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Generative Adversarial Networks: A Novel Perspective from Privacy Protection
Paper and Code
Sep 25, 2019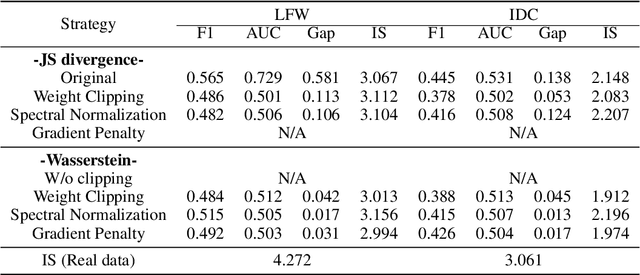
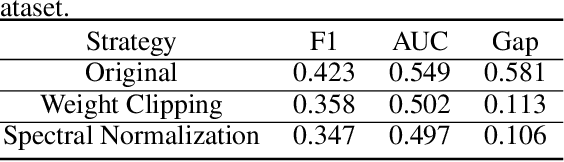
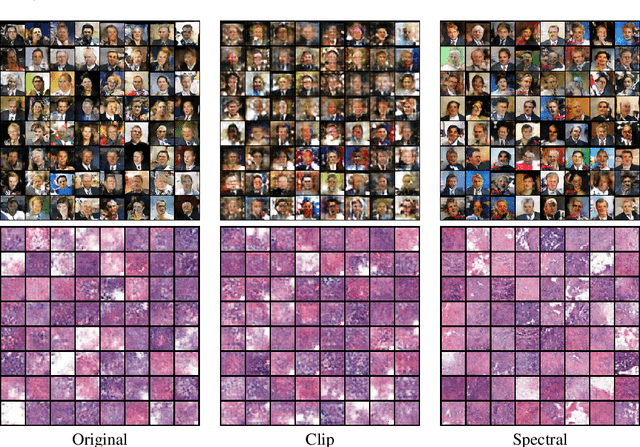
In this paper, we aim to understand the generalization properties of generative adversarial networks (GANs) from a new perspective of privacy protection. Theoretically, we prove that a differentially private learning algorithm used for training the GAN does not overfit to a certain degree, i.e., the generalization gap can be bounded. Moreover, some recent works, such as the Bayesian GAN, can be re-interpreted based on our theoretical insight from privacy protection. Quantitatively, to evaluate the information leakage of well-trained GAN models, we perform various membership attacks on these models. The results show that previous Lipschitz regularization techniques are effective in not only reducing the generalization gap but also alleviating the information leakage of the training dataset.