 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation via Separation: Boosting Facial Landmark Detector with Semi-Supervised Style Translation
Paper and Code

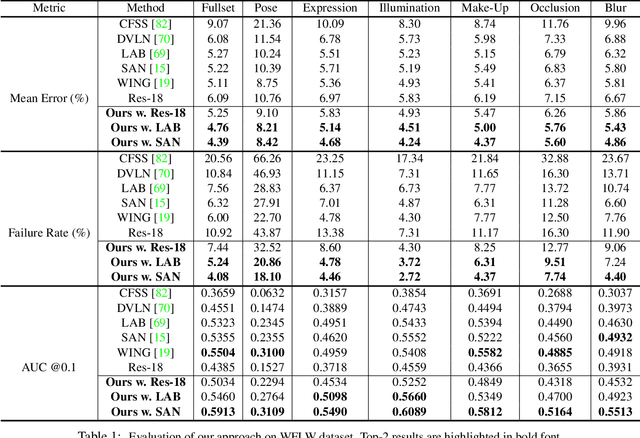
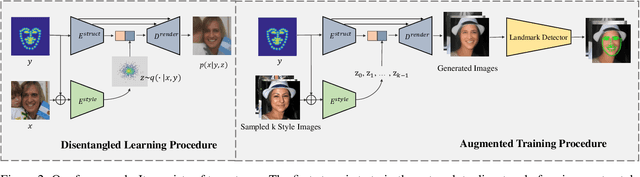
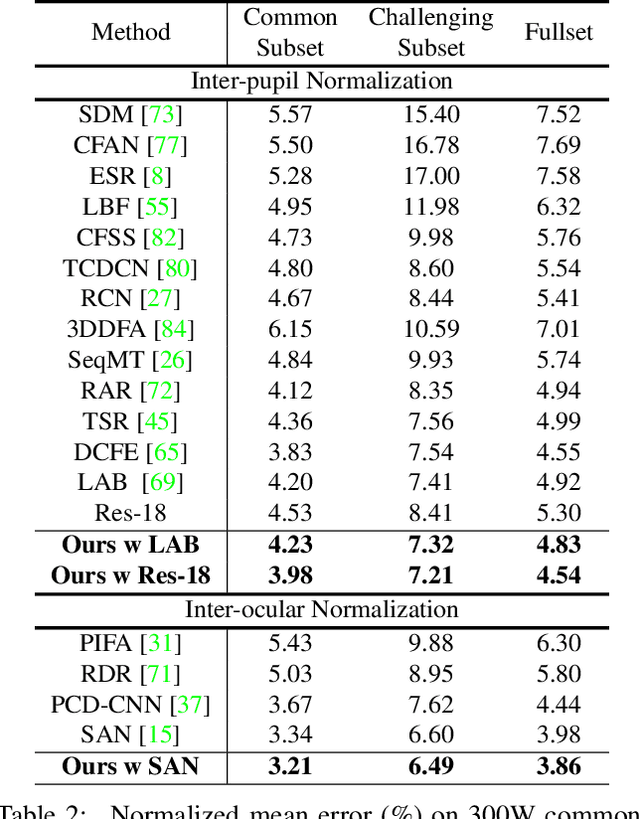
Facial landmark detection, or face alignment, is a fundamental task that has been extensively studied. In this paper, we investigate a new perspective of facial landmark detection and demonstrate it leads to further notable improvement. Given that any face images can be factored into space of style that captures lighting, texture and image environment, and a style-invariant structure space, our key idea is to leverage disentangled style and shape space of each individual to augment existing structures via style translation. With these augmented synthetic samples, our semi-supervised model surprisingly outperforms the fully-supervised one by a large margin. Extensive experiments verify the effectiveness of our idea with state-of-the-art results on WFLW, 300W, COFW, and AFLW datasets. Our proposed structure is general and could be assembled into any face alignment frameworks. The code is made publicly available at https://github.com/thesouthfrog/stylealign.