 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAPS: Towards Better Recognition of Fine-grained Images by Region Attending and Part Sequencing
Paper and Code
Aug 06, 2019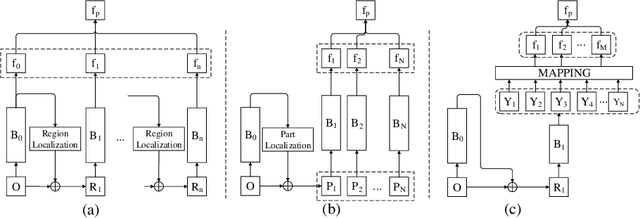
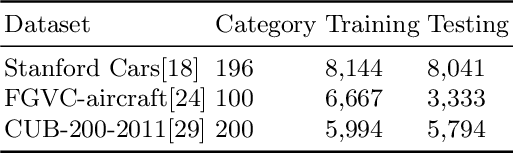

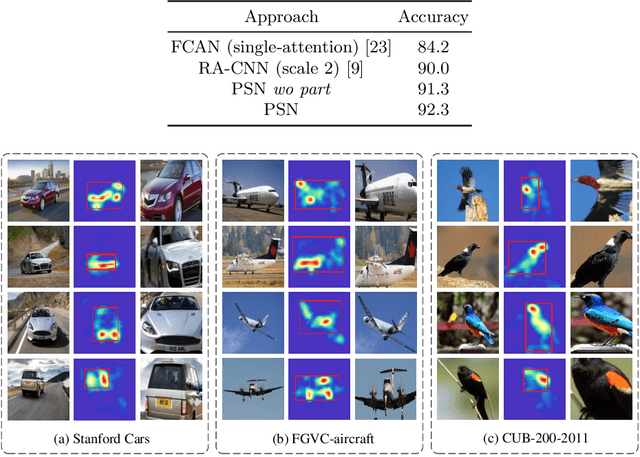
Fine-grained image recognition has been a hot research topic in computer vision due to its various applications. The-state-of-the-art is the part/region-based approaches that first localize discriminative parts/regions, and then learn their fine-grained features. However, these approaches have some inherent drawbacks: 1) the discriminative feature representation of an object is prone to be disturbed by complicated background; 2) it is unreasonable and inflexible to fix the number of salient parts, because the intended parts may be unavailable under certain circumstances due to occlusion or incompleteness, and 3) the spatial correlation among different salient parts has not been thoroughly exploited (if not completely neglected). To overcome these drawbacks, in this paper we propose a new, simple yet robust method by building part sequence model on the attended object region. Concretely, we first try to alleviate the background effect by using a region attention mechanism to generate the attended region from the original image. Then, instead of localizing different salient parts and extracting their features separately, we learn the part representation implicitly by applying a mapping function on the serialized features of the object. Finally, we combine the region attending network and the part sequence learning network into a unified framework that can be trained end-to-end with only image-level labels. Our extensive experiments on three fine-grained benchmarks show that the proposed method achieves the state of the art performance.