 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Paper and Code
Jul 05, 2019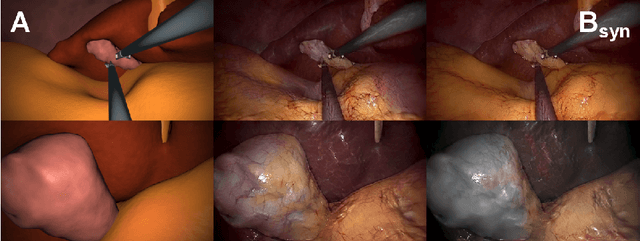
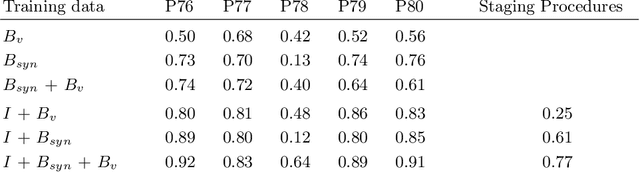
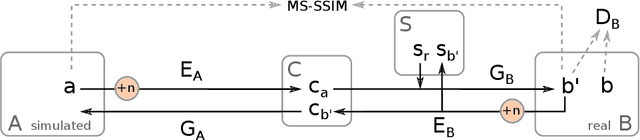
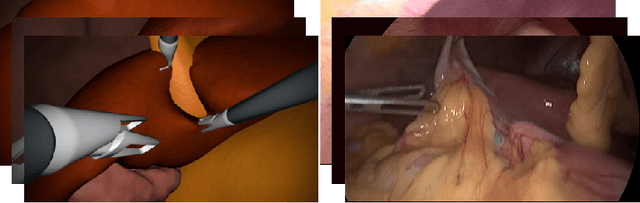
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).