 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelection Via Proxy: Efficient Data Selection For Deep Learning
Paper and Code
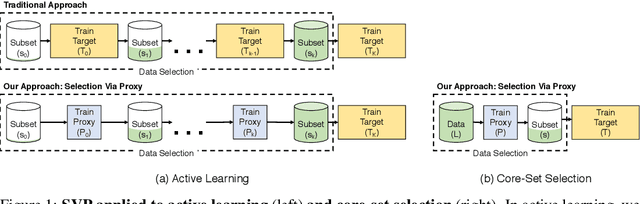
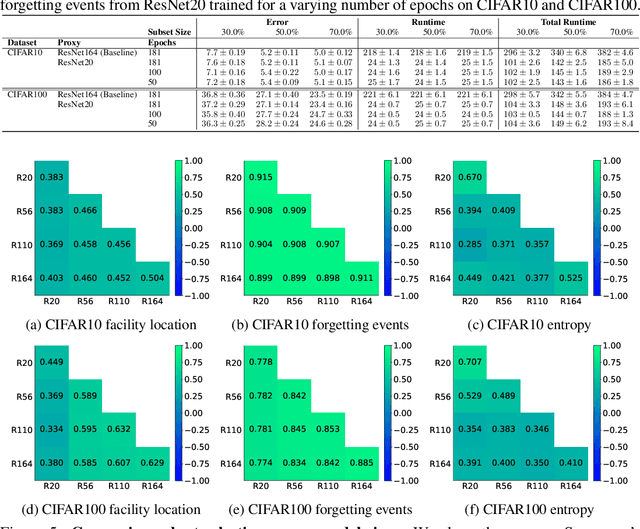
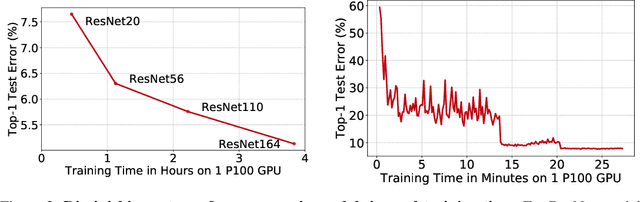
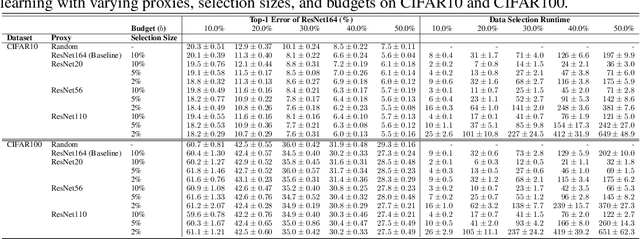
Data selection methods such as active learning and core-set selection are useful tools for machine learning on large datasets, but they can be prohibitively expensive to apply in deep learning. Unlike in other areas of machine learning, the feature representations that these techniques depend on are learned in deep learning rather than given, which takes a substantial amount of training time. In this work, we show that we can significantly improve the computational efficiency of data selection in deep learning by using a much smaller proxy model to perform data selection for tasks that will eventually require a large target model (e.g., selecting data points to label for active learning). In deep learning, we can scale down models by removing hidden layers or reducing their dimension to create proxies that are an order of magnitude faster. Although these small proxy models have significantly higher error, we find that they empirically provide useful rankings for data selection that have a high correlation with those of larger models. We evaluate this "selection via proxy" (SVP) approach on several data selection tasks. For active learning, applying SVP to Sener and Savarese [2018]'s recent method for active learning in deep learning gives a 4x improvement in execution time while yielding the same model accuracy. For core-set selection, we show that a proxy model that trains 10x faster than a target ResNet164 model on CIFAR10 can be used to remove 50% of the training data without compromising the accuracy of the target model, making end-to-end training time improvements via core-set selection possible.