 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Guided Fashion Image Synthesis Using Deep Generative Model
Paper and Code
Jun 17, 2019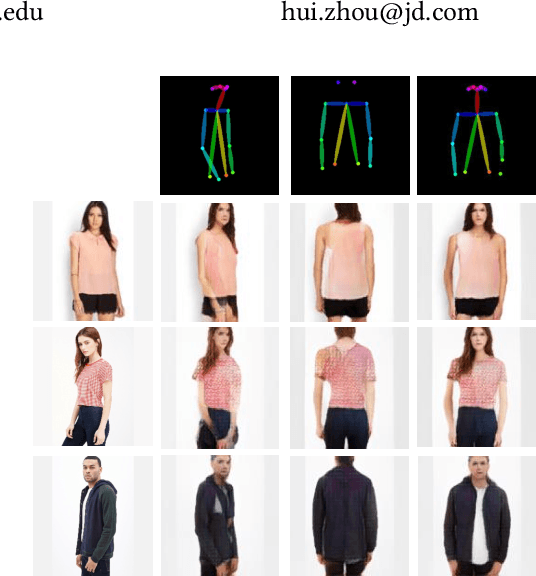
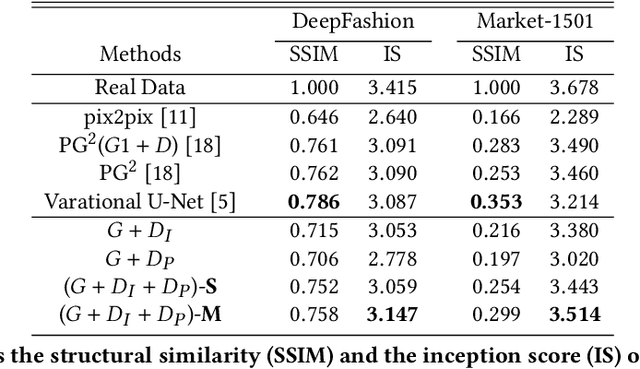
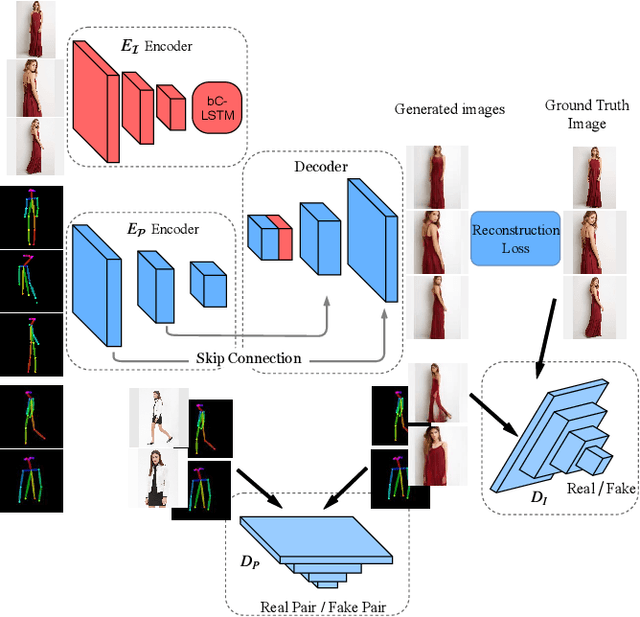

Generating a photorealistic image with intended human pose is a promising yet challenging research topic for many applications such as smart photo editing, movie making, virtual try-on, and fashion display. In this paper, we present a novel deep generative model to transfer an image of a person from a given pose to a new pose while keeping fashion item consistent. In order to formulate the framework, we employ one generator and two discriminators for image synthesis. The generator includes an image encoder, a pose encoder and a decoder. The two encoders provide good representation of visual and geometrical context which will be utilized by the decoder in order to generate a photorealistic image. Unlike existing pose-guided image generation models, we exploit two discriminators to guide the synthesis process where one discriminator differentiates between generated image and real images (training samples), and another discriminator verifies the consistency of appearance between a target pose and a generated image. We perform end-to-end training of the network to learn the parameters through back-propagation given ground-truth images. The proposed generative model is capable of synthesizing a photorealistic image of a person given a target pose. We have demonstrated our results by conducting rigorous experiments on two data sets, both quantitatively and qualitatively.