 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Domain Randomization Distributions for Transfer of Locomotion Policies
Paper and Code
Jun 02, 2019
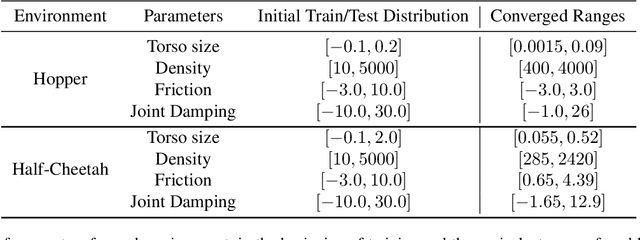
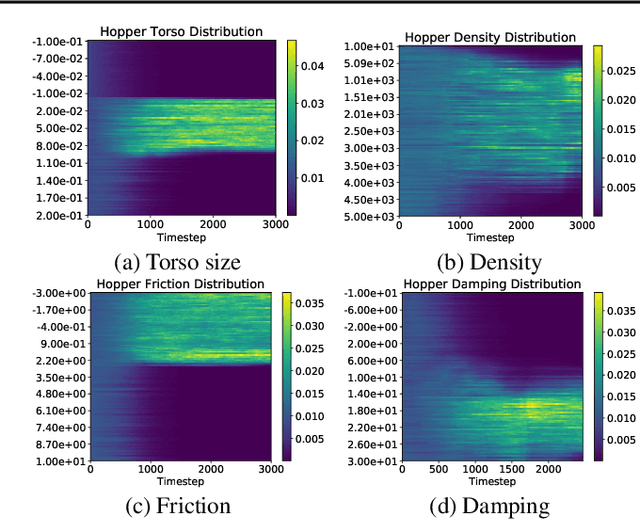
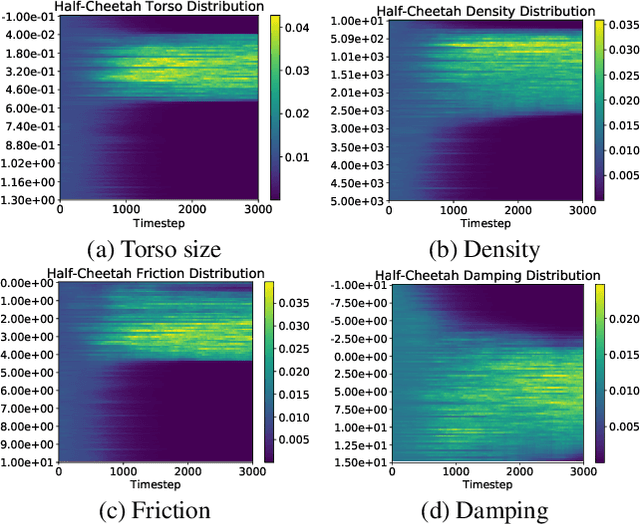
Domain randomization (DR) is a successful technique for learning robust policies for robot systems, when the dynamics of the target robot system are unknown. The success of policies trained with domain randomization however, is highly dependent on the correct selection of the randomization distribution. The majority of success stories typically use real world data in order to carefully select the DR distribution, or incorporate real world trajectories to better estimate appropriate randomization distributions. In this paper, we consider the problem of finding good domain randomization parameters for simulation, without prior access to data from the target system. We explore the use of gradient-based search methods to learn a domain randomization with the following properties: 1) The trained policy should be successful in environments sampled from the domain randomization distribution 2) The domain randomization distribution should be wide enough so that the experience similar to the target robot system is observed during training, while addressing the practicality of training finite capacity models. These two properties aim to ensure the trajectories encountered in the target system are close to those observed during training, as existing methods in machine learning are better suited for interpolation than extrapolation. We show how adapting the domain randomization distribution while training context-conditioned policies results in improvements on jump-start and asymptotic performance when transferring a learned policy to the target environment.