 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Grounded Image Captions without Localization Supervision
Paper and Code
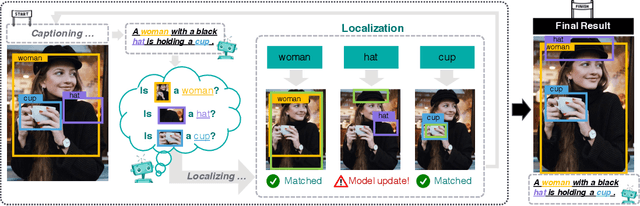
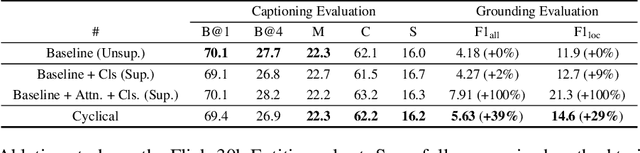
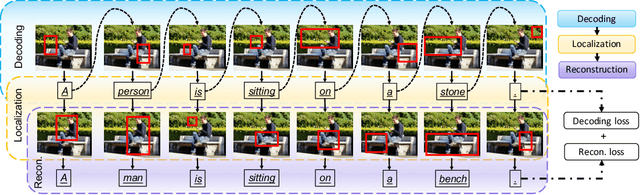
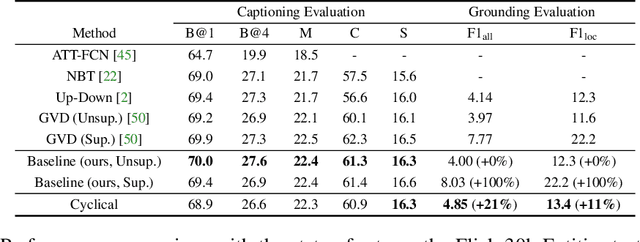
When generating a sentence description for an image, it frequently remains unclear how well the generated caption is grounded in the image or if the model hallucinates based on priors in the dataset and/or the language model. The most common way of relating image regions with words in caption models is through an attention mechanism over the regions that is used as input to predict the next word. The model must therefore learn to predict the attention without knowing the word it should localize. In this work, we propose a novel cyclical training regimen that forces the model to localize each word in the image after the sentence decoder generates it and then reconstruct the sentence from the localized image region(s) to match the ground-truth. The initial decoder and the proposed reconstructor share parameters during training and are learned jointly with the localizer, allowing the model to regularize the attention mechanism. Our proposed framework only requires learning one extra fully-connected layer (the localizer), a layer that can be removed at test time. We show that our model significantly improves grounding accuracy without relying on grounding supervision or introducing extra computation during inference.