 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta reinforcement learning as task inference
Paper and Code
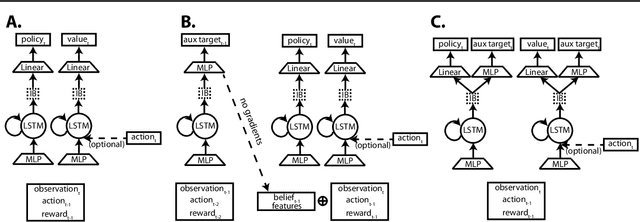
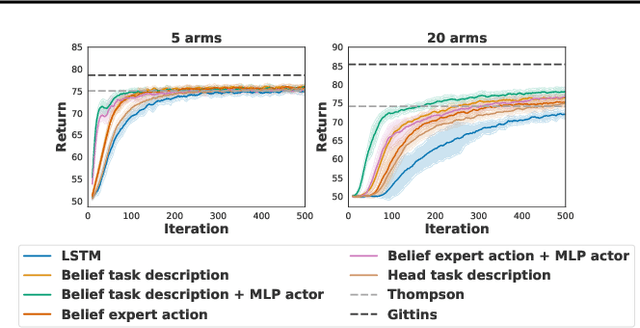
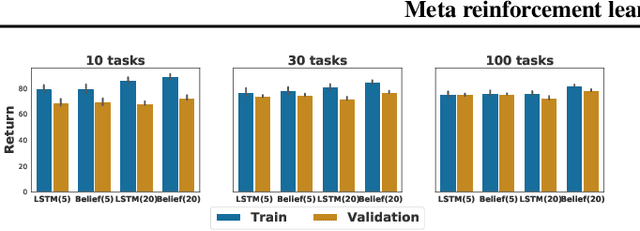

Humans achieve efficient learning by relying on prior knowledge about the structure of naturally occurring tasks. There has been considerable interest in designing reinforcement learning algorithms with similar properties. This includes several proposals to learn the learning algorithm itself, an idea also referred to as meta learning. One formal interpretation of this idea is in terms of a partially observable multi-task reinforcement learning problem in which information about the task is hidden from the agent. Although agents that solve partially observable environments can be trained from rewards alone, shaping an agent's memory with additional supervision has been shown to boost learning efficiency. It is thus natural to ask what kind of supervision, if any, facilitates meta-learning. Here we explore several choices and develop an architecture that separates learning of the belief about the unknown task from learning of the policy, and that can be used effectively with privileged information about the task during training. We show that this approach can be very effective at solving standard meta-RL environments, as well as a complex continuous control environment in which a simulated robot has to execute various movement sequences.