 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Sequence-to-sequence ASR using Unpaired Speech and Text
Paper and Code
Apr 30, 2019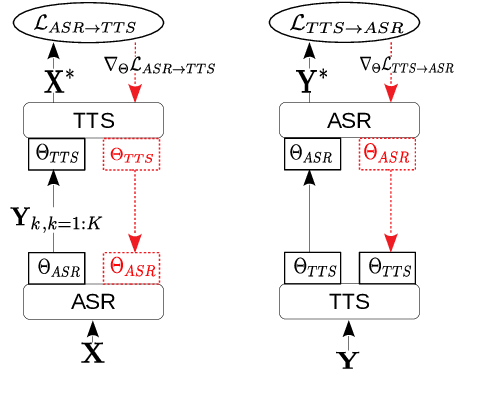
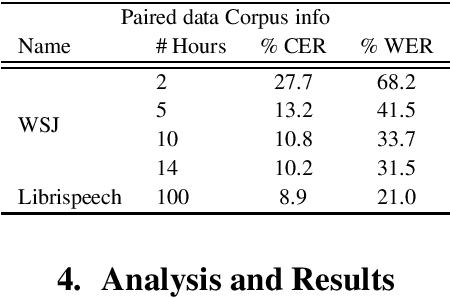
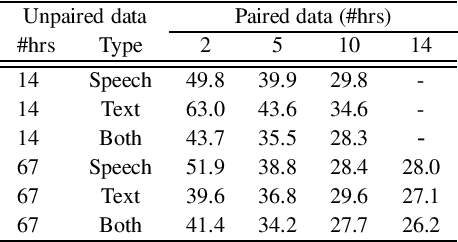
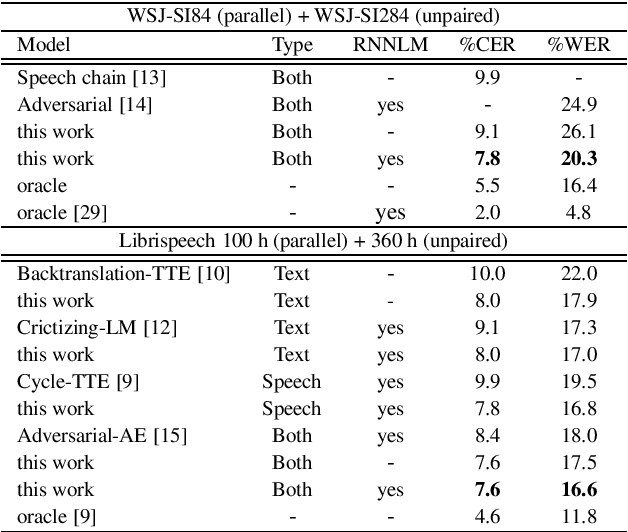
Sequence-to-sequence ASR models require large quantities of data to attain high performance. For this reason, there has been a recent surge in interest for self-supervised and supervised training in such models. This work builds upon recent results showing notable improvements in self-supervised training using cycle-consistency and related techniques. Such techniques derive training procedures and losses able to leverage unpaired speech and/or text data by combining ASR with text-to-speech (TTS) models. In particular, this work proposes a new self-supervised loss combining an end-to-end differentiable ASR$\rightarrow$TTS loss with a point estimate TTS$\rightarrow$ASR loss. The method is able to leverage both unpaired speech and text data to outperform recently proposed related techniques in terms of \%WER. We provide extensive results analyzing the impact of data quantity and speech and text modalities and show consistent gains across WSJ and Librispeech corpora. Our code is provided to reproduce the experiments.