 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Propagate Once: Accelerating Adversarial Training via Maximal Principle
Paper and Code
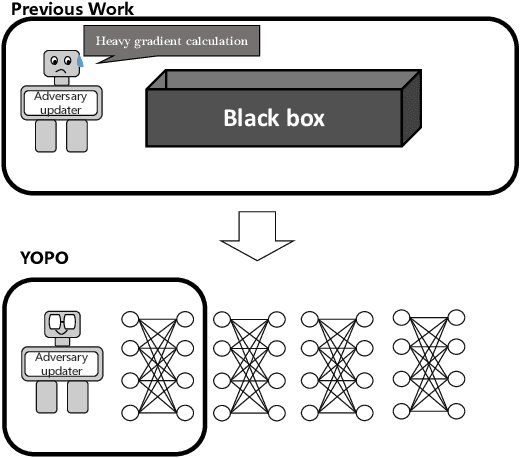
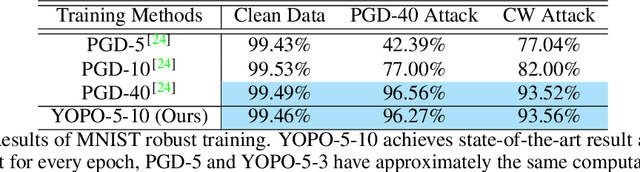
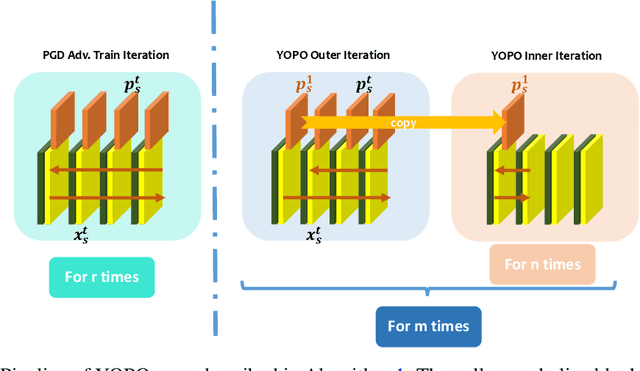
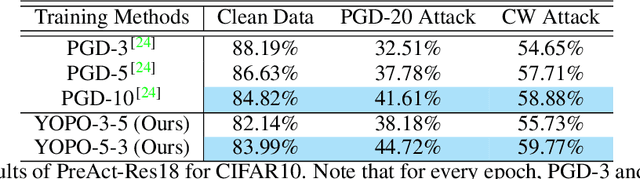
Deep learning achieves state-of-the-art results in many tasks in computer vision and natural language processing. However, recent works have shown that deep networks can be vulnerable to adversarial perturbations, which raised a serious robustness issue of deep networks. Adversarial training, typically formulated as a robust optimization problem, is an effective way of improving the robustness of deep networks. A major drawback of existing adversarial training algorithms is the computational overhead of the generation of adversarial examples, typically far greater than that of the network training. This leads to the unbearable overall computational cost of adversarial training. In this paper, we show that adversarial training can be cast as a discrete time differential game. Through analyzing the Pontryagin's Maximal Principle (PMP) of the problem, we observe that the adversary update is only coupled with the parameters of the first layer of the network. This inspires us to restrict most of the forward and back propagation within the first layer of the network during adversary updates. This effectively reduces the total number of full forward and backward propagation to only one for each group of adversary updates. Therefore, we refer to this algorithm YOPO (You Only Propagate Once). Numerical experiments demonstrate that YOPO can achieve comparable defense accuracy with approximately 1/5 ~ 1/4 GPU time of the projected gradient descent (PGD) algorithm. Our codes are available at https://https://github.com/a1600012888/YOPO-You-Only-Propagate-Once.