 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Guided Unpaired Image-to-Image Translation with Semi-supervised Learning
Paper and Code
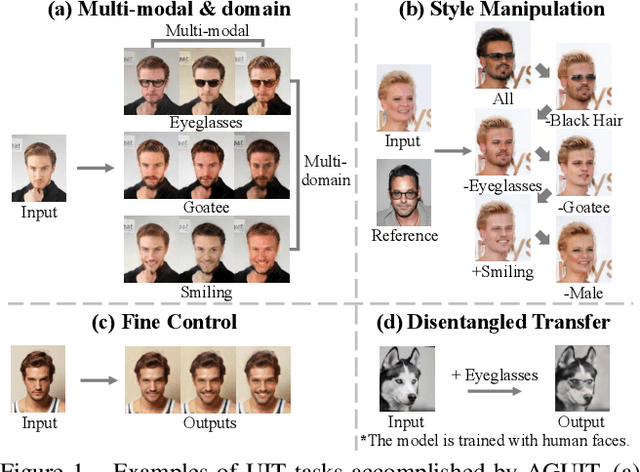

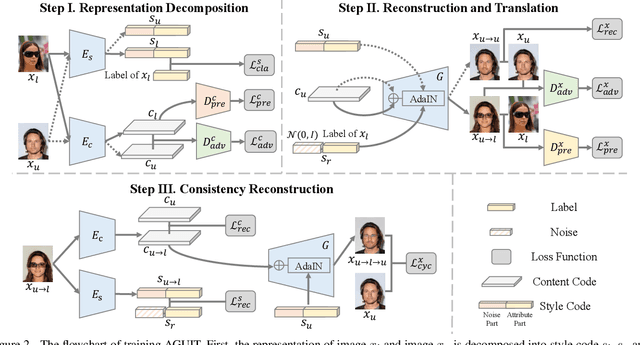
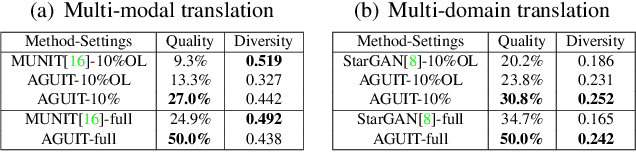
Unpaired Image-to-Image Translation (UIT) focuses on translating images among different domains by using unpaired data, which has received increasing research focus due to its practical usage. However, existing UIT schemes defect in the need of supervised training, as well as the lack of encoding domain information. In this paper, we propose an Attribute Guided UIT model termed AGUIT to tackle these two challenges. AGUIT considers multi-modal and multi-domain tasks of UIT jointly with a novel semi-supervised setting, which also merits in representation disentanglement and fine control of outputs. Especially, AGUIT benefits from two-fold: (1) It adopts a novel semi-supervised learning process by translating attributes of labeled data to unlabeled data, and then reconstructing the unlabeled data by a cycle consistency operation. (2) It decomposes image representation into domain-invariant content code and domain-specific style code. The redesigned style code embeds image style into two variables drawn from standard Gaussian distribution and the distribution of domain label, which facilitates the fine control of translation due to the continuity of both variables. Finally, we introduce a new challenge, i.e., disentangled transfer, for UIT models, which adopts the disentangled representation to translate data less related with the training set. Extensive experiments demonstrate the capacity of AGUIT over existing state-of-the-art models.