 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRERERE: Remote Embodied Referring Expressions in Real indoor Environments
Paper and Code

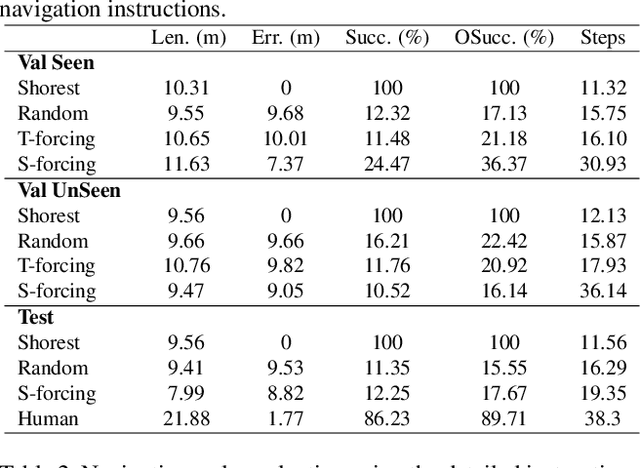

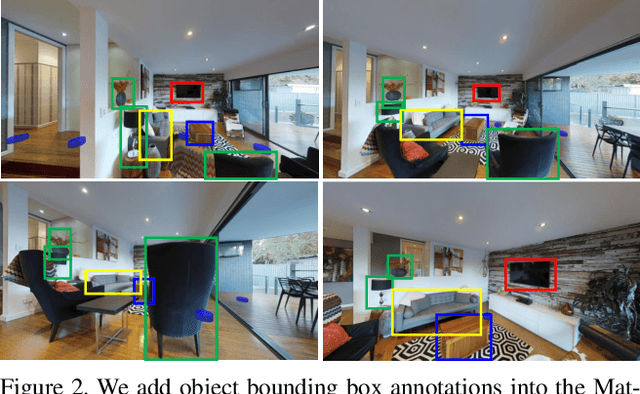
One of the long-term challenges of robotics is to enable humans to communicate with robots about the world. It is essential if they are to collaborate. Humans are visual animals, and we communicate primarily through language, so human-robot communication is inevitably at least partly a vision-and-language problem. This has motivated both Referring Expression datasets, and Vision and Language Navigation datasets. These partition the problem into that of identifying an object of interest, or navigating to another location. Many of the most appealing uses of robots, however, require communication about remote objects and thus do not reflect the dichotomy in the datasets. We thus propose the first Remote Embodied Referring Expression dataset of natural language references to remote objects in real images. Success requires navigating through a previously unseen environment to select an object identified through general natural language. This represents a complex challenge, but one that closely reflects one of the core visual problems in robotics. A Navigator-Pointer model which provides a strong baseline on the task is also proposed.