 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Sensitive Feature Selection by Optimizing F-Measures
Paper and Code
Apr 04, 2019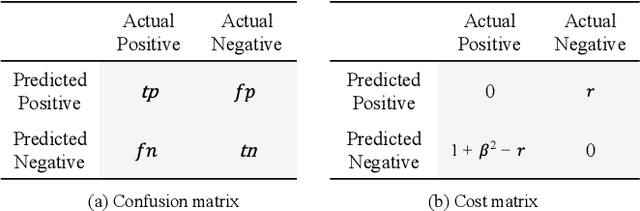
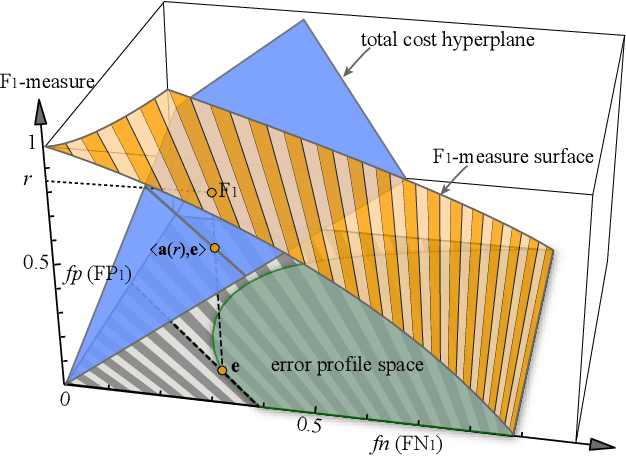
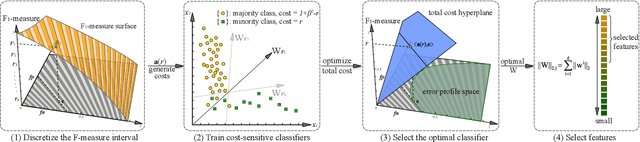
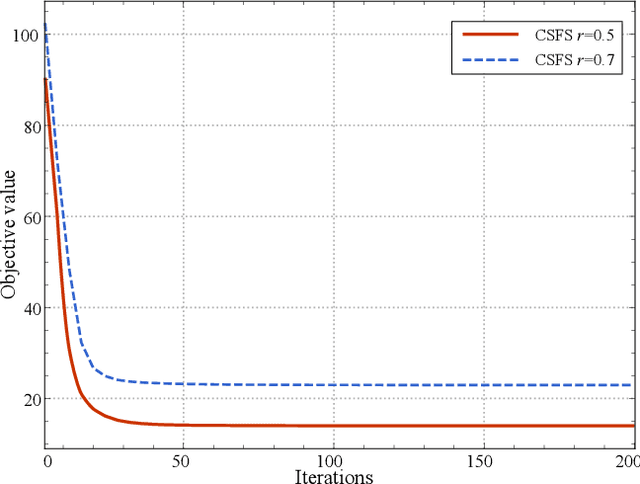
Feature selection is beneficial for improving the performance of general machine learning tasks by extracting an informative subset from the high-dimensional features. Conventional feature selection methods usually ignore the class imbalance problem, thus the selected features will be biased towards the majority class. Considering that F-measure is a more reasonable performance measure than accuracy for imbalanced data, this paper presents an effective feature selection algorithm that explores the class imbalance issue by optimizing F-measures. Since F-measure optimization can be decomposed into a series of cost-sensitive classification problems, we investigate the cost-sensitive feature selection by generating and assigning different costs to each class with rigorous theory guidance. After solving a series of cost-sensitive feature selection problems, features corresponding to the best F-measure will be selected. In this way, the selected features will fully represent the properties of all classes. Experimental results on popular benchmarks and challenging real-world data sets demonstrate the significance of cost-sensitive feature selection for the imbalanced data setting and validate the effectiveness of the proposed method.