 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Robust Convolutional-Attention Network for Irregular Text Recognition
Paper and Code
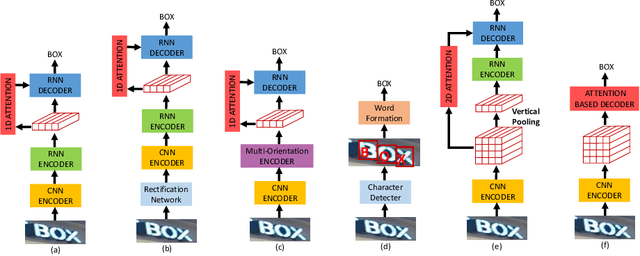
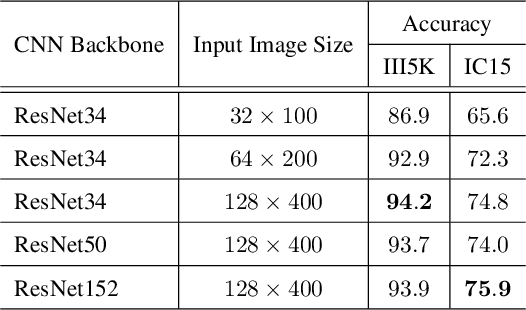
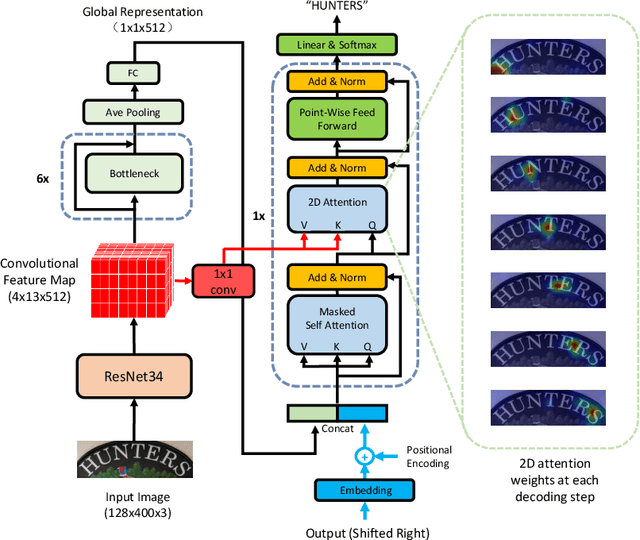
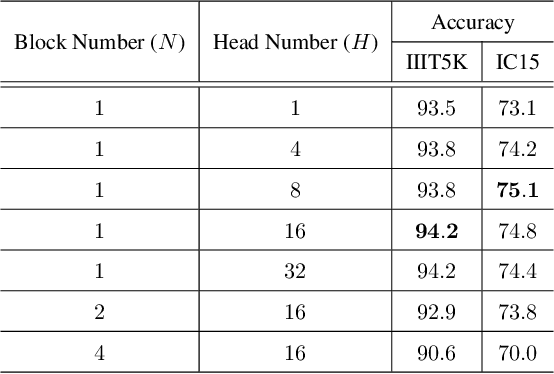
Reading irregular text of arbitrary shape in natural scene images is still a challenging problem. Many existing approaches incorporate sophisticated network structures to handle various shapes, use extra annotations for stronger supervision, or employ hard-to-train recurrent neural networks for sequence modeling. In this work, we propose a simple yet robust approach for irregular text recognition. With no need to convert input images to sequence representations, we directly connect two-dimensional CNN features to an attention-based sequence decoder. As no recurrent module is adopted, our model can be trained in parallel. It achieves 3x to 18x acceleration to backward pass and 2x to 12x acceleration to forward pass, compared with the RNN counterparts. The proposed model is trained with only word-level annotations. With this simple design, our method achieves state-of-the-art or competitive recognition performance on the evaluated regular and irregular scene text benchmark datasets. Furthermore, we show that the recognition performance does not significantly degrade with inaccurate bounding boxes. This is desirable for tasks of end-to-end text detection and recognition: robust recognition performance can still be achieved with an inaccurate text detector. We will release the code.