 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Standardization
Paper and Code
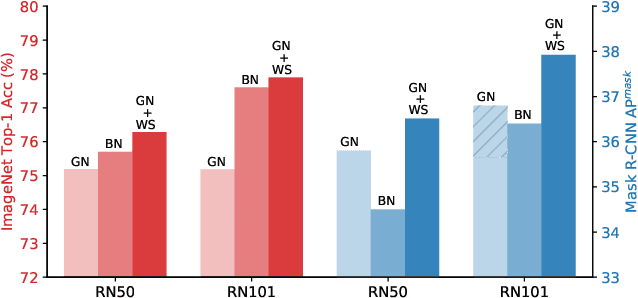

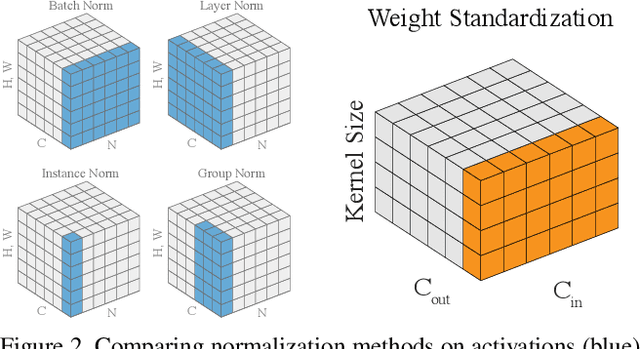
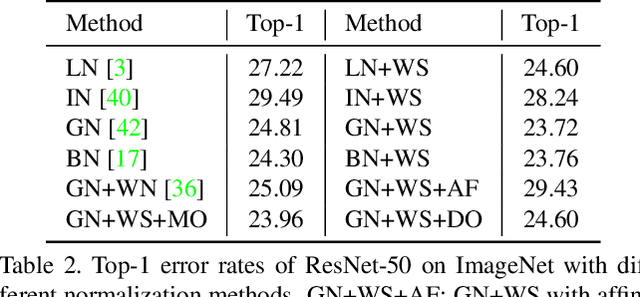
In this paper, we propose Weight Standardization (WS) to accelerate deep network training. WS is targeted at the micro-batch training setting where each GPU typically has only 1-2 images for training. The micro-batch training setting is hard because small batch sizes are not enough for training networks with Batch Normalization (BN), while other normalization methods that do not rely on batch knowledge still have difficulty matching the performances of BN in large-batch training. Our WS ends this problem because when used with Group Normalization and trained with 1 image/GPU, WS is able to match or outperform the performances of BN trained with large batch sizes with only 2 more lines of code. In micro-batch training, WS significantly outperforms other normalization methods. WS achieves these superior results by standardizing the weights in the convolutional layers, which we show is able to smooth the loss landscape by reducing the Lipschitz constants of the loss and the gradients. The effectiveness of WS is verified on many tasks, including image classification, object detection, instance segmentation, video recognition, semantic segmentation, and point cloud recognition. The code is available here: https://github.com/joe-siyuan-qiao/WeightStandardization.