 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Dynamic Boltzmann Softmax Updates
Paper and Code
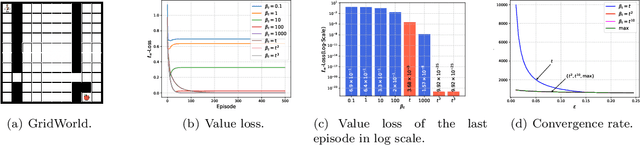
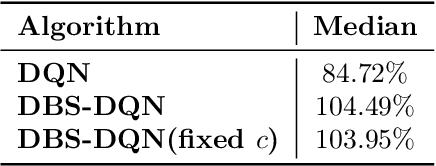
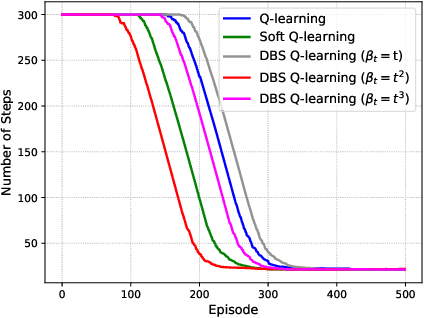
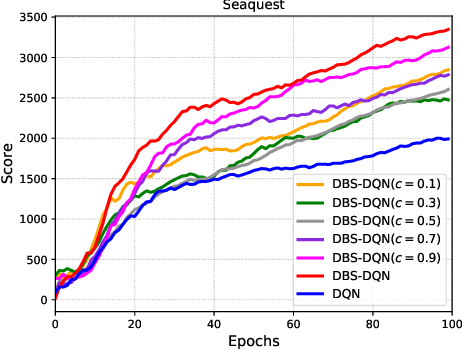
Value function estimation is an important task in reinforcement learning, i.e., prediction. The commonly used operator for prediction in Q-learning is the hard max operator, which always commits to the maximum action-value according to current estimation. Such `hard' updating scheme results in pure exploitation and may lead to misbehavior due to noise in stochastic environments. Thus, it is critical to balancing exploration and exploitation in value function estimation. The Boltzmann softmax operator has a greater capability in exploring potential action-values. However, it does not satisfy the non-expansion property, and its direct use may fail to converge even in value iteration. In this paper, we propose to update the value function with dynamic Boltzmann softmax (DBS) operator in value function estimation, which has good convergence property in the setting of planning and learning. Moreover, we prove that dynamic Boltzmann softmax updates can eliminate the overestimation phenomenon introduced by the hard max operator. Experimental results on GridWorld show that the DBS operator enables convergence and a better trade-off between exploration and exploitation in value function estimation. Finally, we propose the DBS-DQN algorithm by generalizing the dynamic Boltzmann softmax update in deep Q-network, which outperforms DQN substantially in 40 out of 49 Atari games.