 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Unit Exploration for Sequence-to-Sequence Speech Recognition
Paper and Code
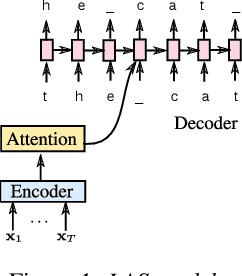
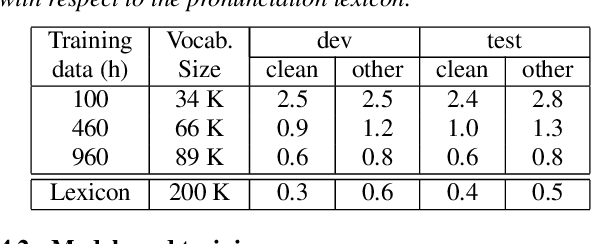
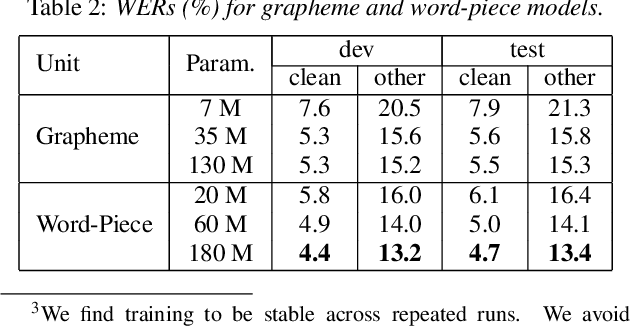
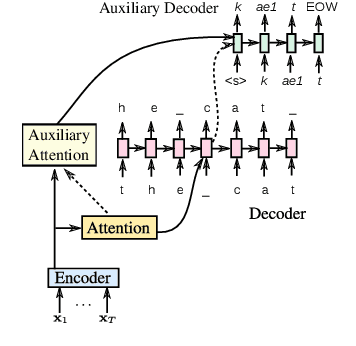
We evaluate attention-based encoder-decoder models along two dimensions: choice of target unit (phoneme, grapheme, and word-piece), and the amount of available training data. We conduct experiments on the LibriSpeech 100hr, 460hr, and 960hr tasks; across all tasks, we find that grapheme or word-piece models consistently outperform phoneme-based models, even though they are evaluated without a lexicon or an external language model. On the 960hr task the word-piece model achieves a word error rate (WER) of 4.7% on the test-clean set and 13.4% on the test-other set, which improves to 3.6% (clean) and 10.3% (other) when decoded with an LSTM LM: the lowest reported numbers using sequence-to-sequence models. We also conduct a detailed analysis of the various models, and investigate their complementarity: we find that we can improve WERs by up to 9% relative by rescoring N-best lists generated from the word-piece model with either the phoneme or the grapheme model. Rescoring an N-best list generated by the phonemic system, however, provides limited improvements. Further analysis shows that the word-piece-based models produce more diverse N-best hypotheses, resulting in lower oracle WERs, than the phonemic system.